 |
Im Jahre 1957 verblüffte der
spätere Nobelpreisträger Herbert A. Simon seine Zuhörer mit
folgender Aussage:
"It is not my aim to surprise or shock you but the
simplest way I can summarize is to say there are now in the world
machines that think, that learn and that create."
Im einzelnen
prophezeite Simon daß innerhalb der nächsten zehn Jahre
ein
Rechner Schachweltmeister wird,
ein Rechner einen wichtigen mathematischen Satz entdecken
wird,
ein Rechner ein beachtliches Musikstück geschrieben haben
wird,
die meisten Theorien in der Psychologie die Form von
Computer Programmen haben werden.
|
| Dieses einfache, auch
"brute force" genannte Verfahren führt beim
Suchen nach interessanten mathematischen Sätzen nicht zum Ziel. Die
Anzahl der interessanten Sätze ist verschwindend klein gegenüber der
riesigen Anzahl von uninteressanten und tautologischen Sätzen.
Bei Anwendungen aus der realen Welt kommt ein weiterer Faktor
erschwerend
hinzu, nämlich die Ungewißheit. In der realen Welt sind oft weder die
Regeln noch die Konfiguration eindeutig bekannt. Trotzdem müssen
Entscheidungen getroffen werden, obwohl nur unvollständige Information
vorliegt. Schon der Schachweltmeister Emanuel Lasker wies daher darauf
hin,
daß Kartenspiele im Grunde ähnlicher zu realen Lebenssituationen sind
als das Schachspiel. "Die Notwendigkeit, die den guten Kartenspieler
zwingt,
einen Plan zu schmieden, der sich auf Wahrscheinlichkeiten gründet, ist
eine prachtvolle Erzieherin. Pläne, die sich auf Gewißheiten
gründen, haben etwas Lebensfremdes."
Das von Lasker formulierte Problem - Entscheidung unter
Ungewißheit
- ist das Hauptproblem von adaptiven Systemen in offenen Welten. Dieses
Problem ist in neuerer Zeit ausführlich von dem Philosophen Karl Popper
untersucht worden. Besonders wichtig sowohl für die künstliche als auch
die natürliche Intelligenz ist Poppers Resultat, daß die Ungewißheit
in offenen Welten nicht als eine Wahrscheinlichkeit im mathematischen
Sinne
interpretiert werden kann. "Hypothesen haben keine
Hypothesenwahrscheinlichkeit." Das unsichere Wissen über die reale Welt
bleibt unsicher. Es gibt, und wird keinen mathematischen Kalkül geben,
der
mit der Unsicherheit "optimal" umgeht.
|
Dieser GMD-SPIEGEL
stellt einige Heuristiken zur Anpassung in offenen Welten
vor. Zum Teil sind sie der Natur abgeschaut, wie die "chromosomale"
Anpassung, die Basis der Evolution ist, und die "cerebrale" Anpassung,
die höhere Lebewesen mit Hilfe ihres Gehirns durchführen. Diese neue
Ausgabe des GMD-SPIEGELS ist eine Fortschreibung von Heft 2'91 über
Neuroinformatik. Dort ist im Editorial zu lesen: "Menschen und Tiere
sind
in ihren jeweiligen Lebensumgebungen zu Höchsleistungen fähig, ohne mit
ihren Sinnesorganen diese Umgebung mathematisch-logisch zu erfassen."
Es
wird noch eine Zeitlang dauern, bis künstliche Systeme in einigen
Teilbereichen auch nur annähernde Leistungen zu den natürlichen
Systemen erbringen werden.

heinz.muehlenbein@online.de
|

 |
Genetische Algorithmen und Evolutionstheorien - Auf der Suche
nach verschollenen Schätzen
Wahrlich, es lohnt sich, eine Sprache zu lernen, die
Philosophen hervorbringt, während die unsere nur Philosophien erzeugt.
Stanislaw Lem
|
Von Heinz Mühlenbein
In Form einer kleinen Detektivgeschichte werden im folgenden
Beitrag die vielen Querbezüge geschildert, die zwischen genetischen
Algorithmen, Populationsgenetik und Evolutionstheorien bestehen. Dabei
wird deutlich, daß die geschichtslose Darstellung der exakten
Wissenschaften dazu geführt hat, daß
wichtige Ergebnisse und Diskussionen in der populationsgenetischen
Forschung
praktisch verschollen sind und im Bereich der genetischen Algorithmen
mühsam wiederentdeckt werden.
In diesem Aufsatz möchte ich am Beispiel meiner eigenen Forschung
ein wichtiges Problem der exakten Wissenschaften vorstellen. Dieses
Problem kann mit dem Wort "Geschichtslosigkeit" umrissen werden. Das
vielschichtige und brüchige Bild, welches auch die exakten
Wissenschaften beim Entstehen neuer Theorien bieten, wird in
nachfolgenden Lehrbüchern geglättet, die vielen Zweifel und Kämpfe beim
Durchsetzen der neuen Theorien werden verschwiegen. Statt dessen wird
ein leidenschaftsloser, anonymer Stil gepflegt, der die mühsam
erstrittene Theorie als notwendig folgend aus ein paar einfachen
Annahmen ableitet.
Ausgangspunkt meiner Forschung war der Wunsch, evolutionäre
Algorithmen im klassischen Sinne der exakten Wissenschaften zu
verstehen. Damit meine ich im wesentlichen die Beantwortung der Frage:
Gegeben sind eine Anfangspopulation, genetische Vererbungsregeln und
eine Fitneßfunktion. Wie wird sich diese Population genetisch nach
mehreren Generationen verändern? Schon bald stellte ich für mich die
Arbeitshypothese auf: Das Züchten von Tieren oder Pflanzen und das
Züchten von künstlichen Organismen auf dem Rechner basieren auf den
gleichen genetischen Modellen. Die Antwort zu meiner Frage sollte sich
daher, zumindest in Ansätzen, in der Populationsgenetik finden. Die
Frage war nur, wo und wie sollte ich suchen? In den letzten vier Jahren
wurde aus meiner Forschung fast eine Detektivgeschichte. Wie in vielen
Detektivgeschichten lassen sich oft nur verwischte Spuren ausmachen,
was die Verfolgung zwar erschwert, aber auch interessant macht.
Manchmal ist das beste Versteck aber auch eines, das gar keines ist.
Das Problem taucht auf
Auf der Suche nach wirkungsvollen parallelen Algorithmen für
Parallelrechner stieß ich 1987 beim Lesen eines wissenschaftlichen
Aufsatzes von Hans-Michael Voigt von der Akademie der Wissenschaften
der ehemaligen Deutschen Demokratischen Republik zufällig auf einen
speziellen evolutionären Algorithmus. Sofort sah ich das Potential
dieser Algorithmenfamilie für Parallelrechner. Bei evolutionären
Algorithmen wird eine Population von virtuellen Individuen parallel in
einer Fitneßlandschaft plaziert. Diese Population exploriert dann mit
Methoden, die der Evolution und der Genetik nachempfunden sind, diese
Landschaft in Richtung besserer Fitneßwerte.
Unser Parallel Genetic Algorithm PGA war schnell konzipiert und nach
einigen Mühen auch auf dem SuperCluster der Firma Parsytec
implementiert. Aus Informatiksicht war der PGA ein idealer paralleler
Algorithmus. Er war asynchron parallel und lief daher mit 100 Prozent
Effizienz auf jedem Parallelrechner (siehe Abbildung 1). Wir haben den
PGA von 1988 bis 1991 erfolgreich zur näherungsweisen Lösung einiger
schwieriger Optimierungsprobleme eingesetzt.
Die wissenschaftliche Analyse des PGA stellte sich aber als
außerordentlich schwierig heraus. Der PGA verwendet Populationen, die
räumliche Nachbarschaften haben. Die virtuelle Population hat einen
zweidimensionalen virtuellen Lebensraum. Die virtuellen Individuen des
PGA suchen selbständig in ihrer Nachbarschaft einen Partner zum
Austausch der Gene aus. Diese Idee macht den Algorithmus asynchron und
lokal.
Getreu der eingangs aufgestellten Hypothese machte ich mich in der
Populationsgenetik auf die Suche. Ich wurde sehr schnell fündig. Das
Problem, welche Populationsstruktur günstiger für die Evolution ist -
räumlich strukturierte Populationen oder unstrukturierte, sogenannte
panmiktische Populationen - wird als Fisher-Wright Problem in fast
allen Lehrbüchern erwähnt. In panmiktischen Populationen kann sich
jedes Individuum mit jedem anderen mit gleicher Wahrscheinlichkeit
paaren. Sir Ronald Fisher und Sewall Wright sind zwei der fünf großen
Populationsgenetiker. Fisher vertrat die Ansicht, daß die Evolution am
günstigsten in großen panmiktischen Populationen verläuft, während
Wright kleine, räumlich strukturierte Populationen favorisierte. Der
Streit zwischen diesen beiden großen Populationsgenetikern konnte mit
mathematischen Mitteln bis heute nicht entschieden werden. In den
heutigen Lehrbüchern findet man meistens die Aussage, daß der Streit
ein Mißverständnis war und im Grunde beide Recht hatten.
Darwin - neu gelesen
Diese Aussage verwunderte mich doch sehr. Daher entschloß ich mich, das
erste Werk der Evolutionsbiologie zu lesen, nämlich -The Origin of
Species by Means of Natural Selection- von Charles Darwin. Hier fand
ich zu meinem Erstaunen eine ausführliche Diskussion meines Problems.
Darwin vertritt die These, daß Raum und Zeit für die Evolution
gleichermaßen wichtig sind. Zu meiner größten Überraschung diskutiert
Darwin sogar ein zyklisches Evolutionsmodell. Darwins Hauptproblem war,
eine Erklärung dafür zu finden, wie die Evolution in relativ kurzer
Zeit auf der Erde so vielfältige Formen hervorbringen konnte. Darwin
sah jeweils andere Vorteile für eine panmiktische Population und für
kleinere, räumlich strukturierte Populationen. Ein Wechsel zwischen
diesen Populationsstrukturen wird erzwungen, wenn man ein zyklisches
Auseinanderbrechen und Zusammenwachsen der Kontinente annimmt. Diese
kühne Hypothese stellt Darwin dann auch auf.
Zum Beweis sei das Originalzitat angeführt, in dem Darwin die
Schlußfolgerung aus seinen detaillierten Überlegungen zieht. "I
conclude that for terrestrial productions a large continental area...
will be the most favourable for the production of many new forms. For
the area will first have existed as a continent, and the inhabitants,
at this period numerous individuals and kinds, will have been subjected
to severe competition. When converted by subsidence into large separate
islands, there will still exist many individuals of the same species on
each island, immigration will be prevented, so that new places in the
polity of each island will have to be filled up by modifications of the
old inhabitants; and time will be allowed for the varieties in each to
become well modified and perfected. When, by renewed elevation, the
islands will be reconverted into a continental area, there will be
again severe competition; the most favoured improved varieties will be
enabled to spread: there will be much extinction of the less improved
forms."
Ich überlasse es dem Leser, diese Fundstelle in dem wunderbaren Buch
von Darwin selber aufzuspüren. Darwins Argument kann so zusammengefaßt
werden: Ein zyklischer Wechsel zwischen einer großen panmiktischen
Population (Fishers Modell) und kleineren, räumlich konzentrierten
Populationen (Wrights Modell) ist für die Evolution günstiger als eine
feste Populationsstruktur. Beide Populationsformen haben ihre
jeweiligen Vorteile. Für mich ist Darwins Ableitung des Zyklus eine der
großen wissenschaftlichen Denkleistungen.
Ich war von Darwins kühner These so beeindruckt, daß ich eine
wissenschaftliche Präzisierung versuchte. In meinem Experiment spielen
die Individuen ein Spiel gegeneinander. Die Fitneß eines Individuums
ergibt sich aus der Anzahl der gewonnenen Spiele. Nach einer Spielrunde
wird die Fitneß verwendet, um die Anzahl der
Paarungen zu bestimmen, die ein Individuum bekommt. Bei jeder Paarung
wird
ein Nachkomme erzeugt. Wenn das Spiel genügend kompliziert war und eine
genügende Anzahl von Generationen simuliert wurde, zeigten die
Simulationen, daß das zyklische Populationsmodell von Darwin in der Tat
am
effizientesten ist.
Die Simulationsresultate habe ich 1991 in einem Aufsatz, "Darwin's
Continent Cycle Theory and Its Simulation by the Iterated Prisoner's
Dilemma", publiziert. Der Aufsatz teilte das Schicksal von Darwins
zyklischem Evolutionsmodell, er wurde in der Biologie nicht zur
Kenntnis genommen. Der Grund hierfür ist einfach anzuführen: Für die
experimentelle Evolutionsbiologie ist das Modell zu theoretisch, für
die mathematische Populationsgenetik zu wenig mathematisch.
Schon während dieser Forschung habe ich mich gefragt, ob es nicht
Evolutionsmodelle gibt, die einfacher zu analysieren sind.

Natürliche Selektion oder Züchtung?
Darwin begründet seine Evolutionstheorie der "natural selection" im
wesentlichen mit der offensichtlich erfolgreich angewendeten
"artificial selection" durch die menschlichen Züchter. Die
wissenschaftlich betriebene Tierzucht ist eine gezielte Optimierung von
Merkmalen. Ob die natürliche Evolution überhaupt optimiert, ist eine
offene Frage. Für mich ist die natürliche Evolution eher ein
permanenter Anpassungsprozeß.
Für die Optimierung auf dem Rechner erscheint daher die Tierzucht
ein viel besseres Modell zu sein. Beim Konzipieren dieser neuen Klasse
von genetischen Algorithmen hatte ich zwei Hoffnungen: erstens, daß der
neue Algorithmus erheblich schneller optimiert als der alte, und
zweitens, daß er einfacher zu analysieren ist. Der entsprechende
Algorithmus, der Breeder Genetic Algorithm BGA, war schnell entworfen
und implementiert. Der Hauptunterschied zwischen dem PGA und dem BGA
liegt in der Selektion. Während beim PGA die Selektion durch die
Individuen selbstorganisierend ohne zentrale Kontrolle abläuft, wird
die Selektion beim BGA zentral durch einen virtuellen Züchter
durchgeführt.
Bei großen Nutztierpopulationen verwenden die Züchter übrigens
häufig eine Schwellenwertselektion. Nur die besten T Prozent der Tiere
werden zur Fortpflanzung zugelassen. Erste Simulationsergebnisse
bestätigten, daß der BGA bei weitem effizienter optimiert als der PGA.
Leider zeigte es sich sehr bald, daß auch die mathematische Analyse des
BGA nicht mit bekannten Verfahren der Populationsgenetik durchgeführt
werden kann. Selbst der einfachste BGA hat noch sechs wesentliche
Parameter
- die Größe der Population N,
- die Länge des Chromosoms n,
- die Anfangspopulation P(0),
- den Schwellwert der Selektion T,
- die Mutationsrate m,
- den Rekombinationsoperator r.
Diese Parameter beeinflussen das dynamische Verhalten des BGA meistens
nichtlinear. Daher ist eine Beantwortung der naheliegenden Frage
äußerst schwierig: Was sind die optimalen Parameter des BGA, um
Individuen mit guten Fitneßwerten, das heißt gute Lösungen der
Optimierungsaufgabe, möglichst effizient zu erhalten? Eine Möglichkeit,
diese Frage zu beantworten, besteht in der Anwendung der klassischen
Technik
der Reduktion: Man variiere wenige Parameter und halte die übrigen
fest.
Für den BGA haben wir die Methoden und Verfahren der Züchtung
übernommen. Eine Züchtung kann als wissenschaftlich bezeichnet werden,
wenn die Ziele quantifiziert werden. Im allgemeinen ist das Ziel der
Züchter die Verbesserung der mittleren Fitneß der Population.
Ausgangspunkt der wissenschaftlichen Züchtung ist die Gleichung für den
Selektionserfolg
R(t) = b(t)*S(t)
In der Gleichung bedeutet t die Generation, R(t) ist die Differenz
der mittleren Fitneß von Population t und t+1, S(t) ist das
Selektionsdifferential. Dieses ist definiert als Differenz der
mittleren Fitneß der selektierten Population (der Eltern von Population
t+1) und der gesamten Population t. Das Selektionsdifferential
quantifiziert die Stärke der Selektion. Die Grundannahme der Gleichung
ist nun klar: es wird ein Zusammenhang zwischen der Stärke der
Selektion und dem Selektionserfolg postuliert. Der
Proportionalitätsfaktor b(t) wird die realisierte Vererbbarkeit
genannt. Falls b(t) = 1 ist, wirkt sich die Selektion vollständig auf
die Kinder aus. Wenn b(t) = 0 ist, gibt es überhaubt keinen
Zusammenhang zwischen Selektion und Selektionserfolg.
Meine Spurensuche nach dem "Erfinder" dieser Gleichung war bisher
erfolglos. Mein augenblicklicher Kenntnisstand ist, daß Wilhelm
Johannssen
schon 1903 die Gleichung verwendete, um Bohnen mit großem Gewicht zu
züchten. In den meisten Standardwerken der Populationsgenetik wird
diese
Gleichung überhaupt nicht mehr erwähnt. Nach dem zweiten Weltkrieg hat
sich die Populationsgenetik auch praktisch geteilt - eine, die anhand
theoretischer Modelle die natürliche Evolution untersucht, eine zweite,
die praktische Züchtungsprobleme behandelt.
Weitere Spurensuche brachte an den Tag, daß der Begriff
Vererbbarkeit in der Populationsgenetik unterschiedlich verwendet wird.
Dies führt zu Verwirrungen bis zum heutigen Tag. Vererbbarkeit wurde
schon 1867 von Francis Galton, dem Vetter von Darwin, eingeführt.
Galton hat als erster versucht, die Evolutionstheorie von Darwin zu
quantifizieren. In einer für die damalige Zeit großangelegten
experimentellen Studie untersuchte Galton, ob es eine Beziehung
zwischen der Größe der Eltern und der ihrer Kinder gibt. Seine
Originalgrafik aus dem Jahr 1887 ist in Abbildung 2 abgedruckt. Nach
kleinerer "Bereinigung" der Daten stellte Galton empirisch eine Reihe
von "Gesetzen" auf. Wie viele große Gesetze wurden sie folgendermaßen
gefunden: "At length, one morning, while waiting at a roadside station
near Ramsgate for a train and poring over the diagram in my notebook,
it stuck me that the lines of equal frequency ran in concentric
ellipses. The cases were too few for my certainty,
but my eye, being accustomed to such things, satisfied me, that I was
approaching the solution."
Dieses Aufspüren der Ellipsen wurde von Karl Pearson, einem Schüler
von Galton, folgendermaßen kommentiert. Er schrieb 1920: "That Galton
should have evolved all this from his observations is to my mind one of
the most noteworthy scientific discoveries arising from pure analysis
of observations". Dieser Bemerkung kann man nur zustimmen.
Aus der grafischen Darstellung wird für den Fachmann in der
Statistik auch deutlich, wie kompliziert Galton seine größte Erfindung
- die Korrelation r zwischen Eltern und Kindern bestimmt hat. Mit der
Korrelation eng verbunden ist die lineare Regression
K = b*(M+V)/2 + a
Hier bedeutet K die durchschnittliche Größe der Kinder, M ist die
Größe der Mutter und V die des Vaters. a gibt die Verschiebung der
durchschnittlichen Größe an. Die Steigung der Geraden, b, nannte Galton
die Vererbbarkeit.
Galton ermittelte eine Vererbbarkeit von b=0,8 für die
Größe. Da die Steigung kleiner als 1 ist, ergibt sich: Eltern, die
kleiner sind als der Durchschnitt, haben Kinder, deren Größe näher
am Durchschnitt aller Kinder liegt als ihre eigene - haben also relativ
gesehen größere Kinder. Bei Eltern, die größer sind als der
Durchschnitt ist dies genau umgekehrt. Der Aristrokat Galton nannte
daher
seine Gerade Regression, interpretiert als "regression to
mediocrity". Die heute noch gebräuchliche Version von Korrelation und
Regression ist von Pearson entwickelt worden. Auf der einen Seite ist
diese
mathematisch viel einfacher als die Version von Galton, andererseits
ist die
grafische Interpretation auf der Strecke geblieben.
Galton erklärte übrigens sein Problem und seine empirischen Gesetze
dem Mathematiker Hamilton Dickson. Dieser konnte schnell zeigen, daß
die Gesetze rein mathematisch folgen, wenn die Größe der Kinder und
Eltern wie eine zweidimensionale Normalverteilung zusammenhängen. Nach
Dicksons Antwort schrieb Galton: "I certainly never felt such a glow of
loyalty and respect towards the sovereignty and wide sway of
mathematical analysis, as when his answer arrived, confirming by purely
mathematical reasoning my various and laborious statistical conclusions
with far more minuteness than I had dared to hope."
Pearson wiederholte Galtons Untersuchung und bestätigte im
wesentlichen
die früheren Ergebnisse. Pearson wird mit Recht als der Begründer der
modernen Statistik bezeichnet. Diese wurde damals noch Biometrics
genannt, da
viele Probleme der Statistik aus der Biologie und speziell der
Vererbungsforschung kamen.
Der Biologismus
Meine Spurensuche brachte aber auch etwas anderes ans Licht. Galton
gilt durch sein Werk "Hereditary genius, its laws and consequences"
(1869) als Mitbegründer des eugenischen Programms. Eugenik leitet sich
aus dem Griechischen ab und bedeutet gute Abstammung. Galton hat die
Eugenik als Wissenschaft von der Verbesserung des Menschen durch
Züchtung definiert. Bis Ende der zwanziger Jahre wurde die eugenischen
Bewegung von allen namhaften Forschern speziell im angelsächsischen
Bereich unterstützt. Diesen vielleicht wichtigsten Zweig unserer
Detektivgeschichte kann ich hier nicht weiter verfolgen. Eine
ausgezeichnete Spurensicherung ist bereits durchgeführt. Dem
interessierten Leser empfehle ich ausdrücklich das Buch "Die Träume der
Genetik", 1985 herausgegeben von Ludger Weiß.
Auch ohne die ausführliche Diskussion der Eugenik-Problematik möchte
ich jedoch folgendes feststellen. Der Biologismus, das heißt die
leichtfertige Anwendung von sogenannten biologischen Gesetzen auf
menschliche und gesellschaftliche Probleme, ist eine permanente Gefahr.
Unrühmlicher Höhepunkt des modernen Biologismus ist für mich weiterhin
das Buch "Das Prinzip Eigennutz - Zur Evolution sozialen Verhaltens"
von Wolfgang Wickler und Uta Seibt, Neuausgabe 1991. Nach den Autoren
gibt die soziale Grundformel
Z * r > E
die "Grenzen an, die sozialer Hilfeleistung von der natürlichen
Selektion gesetzt sind". Z und E stehen für den Zuwachs und die Einbuße
an Ausbreitungschancen der Gene, beziehen sich also auf den
Fortpflanzungserfolg. r kennzeichnet den Verwandtschaftsgrad. Er wird
berechnet aus der Anzahl gemeinsamer Gene. So ergibt sich zum Beispiel
r=0,5 als Grad für die Eltern-Kind Beziehung, r=0,25 als Grad für die
Großeltern-Enkelkind Beziehung. Das Gesetz wird folgendermaßen
verdeutlicht: "Hilfeleistungen lohnen sich um so mehr, je näher
verwandte Individuen davon profitieren... Der ideale Lebensretter
(eines ertrinkenden Kindes) wäre (1.) gesund und körperlich stark, (2.)
steril oder über das zeugungsfähige Alter hinaus... und hätte (3.) nur
wenige lebende Verwandte. Retten sollte er am vorteilhaftesten seine
eigene junge Mutter, die viele unselbständige Kinder hat."
Diese Aussagen sind für mich immer noch ein Rätsel. Wie wird das
ertrinkende Kind zur jungen Mutter eines körperlich starken
Erwachsenen? Aber vielleicht ist es im Max-Planck Institut Seewiesen
inzwischen gelungen, daß die Kinder ihre eigenen Eltern zeugen?
Chartisten gegen Fundamentalisten
Die rein phänomenologische Betrachtungsweise der Biometriker hat zu
unzweifelhaft großen Erfolgen in der Züchtung geführt. Diese Technik
haben wir auch beim BGA erfolgreich einsetzen können. Ausgehend von der
Gleichung für den Selektionserfolg können wir beim BGA die genetische
Entwicklung der künstlichen Population auf dem Rechner mathematisch für
einfache Fitneßfunktionen vorhersagen. Bei schwierigen Fitneßfunktionen
schätzen wir die realisierte Vererbbarkeit während der ersten
Generationen ab. Wenn die Vererbbarkeit zu klein wird, wird der BGA
Lauf abgebrochen. In einem solchen Fall führt auch in der Simulation
die Selektion besserer Individuen nicht zu einer Verbesserung der
Fitneß der Population.
Die phänemonologische Betrachtungsweise berücksichtigt keinerlei
Genetik, sie extrapoliert nur aus vergangenen Selektionsexperimenten.
Es werden die Vorhersagen allein aufgrund einer "Chart" gemacht.
Darunter ist das vor allem im Bereich der Aktienkurse populäre
Verfahren zu verstehen, aus dem Kurvenverlauf in der Vergangenheit auf
den Verlauf in der Zukunft zu schließen. Nun drängt sich natürlich die
Frage auf, ob eventuell eine bessere Vorhersage zu erzielen ist, wenn
man ein genetisches Modell mitberücksichtigt. Mathematisch bedeutet
dies, ein genetisches Zufallsmodell auf mikroskopischer Ebene (Gene)
zur Vorhersage von makroskopischen Eigenschaften (Phäne) zu verwenden.

Nachdem wir so kombiniert hatten, machten wir uns wieder auf die
Suche. Die Populationsgenetik mußte vor demselben Problem gestanden
haben. Nach Wiederentdeckung der von Gregor Mendel aufgestellten
Vererbungsgesetze war die Populationgenetik im Besitze eines
genetischen Modells (siehe Abbildung 3). Die Ableitung der bekannten
Gesetze der Biometrie aus den Mendelschen Gesetzen stellte sich aber
als außerordentlich schwierig heraus. Trotzdem behaupteten die
Mendelianer (die Fundamentalisten), daß die Mendelschen Gesetze die
Grundlagen aller Vererbungsmechanismen beschreiben. Diese Behauptung
wurde von Pearson in einer Publikation im Jahre 1904 angegriffen. Er
wies darauf hin, daß es so etwas wie eine "allgemeine Theorie Mendels"
nicht gibt. Fast für jedes einzelne genetische Experiment muß eine
spezielle Form der Vererbung angenommen werden. Zu nennen sind hier die
Unterscheidungen in dominante, rezessive oder lineare Gene. Am Schluß
schreibt Pearson: "The present investigation shows that in the
Mendelian theory there is nothing in essential opposition to the broad
features of linear regression used in the biometric description. But it
does show that the generalized theory (of Mendel) dealt with is not
elastic enough to account for the numerical values of the constants of
heredity hitherto observed."
Unsere BGA Simulationen haben bisher Pearsons Beobachtung leider
bestätigt. Es ist uns nicht gelungen, die Vererbbarkeit allein aus der
Fitneßfunktion mit Hilfe des implementierten genetischen Modells zu
bestimmen.
Pearsons Publikation wird in allen gängigen Lehrbüchern übergangen.
Statt dessen wird die orthodoxe Theorie vertreten, daß Fisher mit
seinen beiden Arbeiten von 1918 und 1922 die große Synthese geschafft
hat. Fisher "bewies", daß unter bestimmten Annahmen aus den Mendelschen
Gesetzen die biometrischen Vererbungsgesetze folgen. Eine genaue
Analyse von Fishers Arbeiten zeigt, daß sie mathematisch ziemlich
abstrus sind. Im Grunde nimmt Fisher eine unendliche Zahl von Genen an,
die alle linear und unendlich klein das gewählte Merkmal beeinflussen.
Fishers Synthese hat zur stürmischen Entwicklung der mathematischen
Populationsgenetik geführt. Die für die Analyse selbst einfacher
genetischer Modelle notwendigen mathematischen Methoden wurden
allerdings bald so schwierig, daß die mathematische Populationsgenetik
ihre Bedeutung innerhalb der experimentellen Biologie verlor. Im Jahre
1959, am einhundertsten Jahrestag des Erscheinens von Darwins "Origin
of Species" kritisierte der Evolutionsbiologe Ernst Mayr: "In order to
permit mathematical treatment numerous simplifying assumptions had to
be made... Evolutionary change was essentially presented as an input or
output of genes, as the adding of certain beans to a beanbag and the
withdrawing of others. This period of Ôbeanbag geneticsŐ was a
necessary step in the development of our thinking, yet its shortcomings
became obvious as a result of the work of experimental population
geneticists."
Ich denke, daß Ernst Mayr im wesentlichen Recht hat. Die Modelle der
Populationsgenetik sind viel zu einfach, um die natürliche Evolution zu
beschreiben. Sie sollten sich aber als überaus geeignet für das
theoretische Verständnis genetischer Algorithmen erweisen.
Hat Mendel gemogelt?
Unter dieser �berschrift wurde 1964 die �ffentlichkeit durch viele
Tageszeitungen in den USA und dann auch in Deutschland aufgeschreckt.
Was war geschehen? Ein Journalist hatte eine Arbeit von Fisher aus dem
Jahr 1936 gefunden, wo dieser vermutet hatte, daß Mendel die Daten
seiner Erbsenversuche geschönt hat. Wie kam Fisher zu dieser These? Aus
einer statistischen Theorie zum Testen von Hypothesen leitete Fisher
ab: die Streuung der Ergebnisse der Experimente sei viel geringer
ausgefallen als aufgrund des von Mendel aufgestellten genetischen
Zufallsmodells zu erwarten gewesen wäre. Mit anderen Worten: Die
Resultate von Mendel sind viel zu nahe am Durchschnitt, der sich in
einer unendlich großen Population ergeben würde. Fisher schrieb:
"...the general level of agreement between Mendel's expectations and
his reported results shows that it is closer than would be expected in
the best of several thousand repetitions... After examining various
possibilities, I have no doubt that Mendel was deceived by a gardening
assistant, who knew only too well what his principal expected from each
trial made." Sollte es sein, daß der Gärtner der eigentliche Entdecker
ist? Oder schlimmer noch: Verdanken wir einem Fälscher die
grundlegenden Vererbungsgesetze?
Einer der wenigen Rehabilitierungsversuche Mendels wurde durch den
Bonner Botaniker und Mendelforscher Franz Weiling durchgeführt. Ich
glaube nicht, daß Fishers Argumente mathematisch widerlegt werden
können. Unter seinen Annahmen sollte man zu seinen Schlußfolgerungen
kommen. Das Problem kann am einfachsten durch Wiederholung der
Mendelschen Versuche gelöst werden. Anscheinend ist dieses aber bis
heute nicht getan worden!
Braucht die Evolution überhaupt Selektion?
Aufgrund der mangelnden Akzeptanz in der experimentellen Biologie ist
die Populationsgenetik mehr und mehr zu einer esoterischen
Geheimwissenschaft mit wirklichkeitsfremden Spielmodellen geworden. Aus
diesem Zustand ist sie erst 1982 aufgewacht, als Motoo Kimura die
Neutralitätstheorie der molekularen Evolution vorstellte. "Dieses Buch
stellt meinen Versuch dar, die wissenschaftliche Welt davon zu
überzeugen, daß die Hauptursache der evolutiven Veränderung auf
molekularer Ebene - also der Veränderung im genetischen Material selbst
- die Zufallsfixierung von selektiv neutralen mutanten Allelen ist und
nicht die positive Darwinsche Selektion".
Die unter Verwendung schwierigster Mathematik (Diffusionsgleichung)
von Kimura gewonnenen Ergebnisse haben wir aufgrund von Simulationen
mit unseren genetischen Algorithmen bestätigt und zum Teil erweitert.
Das Hauptergebnis besagt, daß eine haploide genetische Population der
Größe N, die sich zufällig paart - ganz ohne Selektion, in
durchschnittlich 1.4N*ln(n) Generationen nur aus einem einzigen Genotyp
besteht. n ist die Anzahl der Gene. Der Biologe spricht davon, daß alle
Gene fixiert sind. Rekombination allein kann in einer solchen
Population keine Veränderungen mehr schaffen.
Dieses Resultat hat auch für genetische Algorithmen große
Bedeutung. Die naive Annahme, daß mit schwacher Selektion das Optimum
auf
jeden Fall erreicht wird, ist falsch. Die Zufallskreuzungen in einer
endlichen Population vermindern die genetische Varianz so stark, daß
die
Population bald nur aus einem einzigen Genotyp besteht.
Warum denn nur zwei Eltern
Das Bergen der Schätze der Populationsgenetik hat mich in die Lage
versetzt, den BGA wissenschaftlich zu fundieren. Die mathematischen
Gleichungen, die das dynamische Verhalten des BGA beschreiben, waren
aber selbst für einfache Fitneßfunktionen nur näherungsweise gültig.
Grund hierfür ist, daß die Rekombination der Gene von zwei Eltern zu
einem sogenannten Kopplungsungleichgewicht zwischen den Genen führt.
Die Genhäufigkeiten entfernen sich vom Hardy-Weinberg Gleichgewicht.
Das Hardy-Gleichgewicht ergibt sich, wenn die Genotypen binomial in der
Population verteilt sind.
In Zusammenarbeit mit dem Populationsgenetiker Günther Wagner haben
wir die exakten Gleichungen für die Verbreitung der Gene mit einem
Programm berechnet. Eine analytische Lösung der Gleichungen erscheint
unmöglich. Die Populationsgenetiker haben schon die vier Gleichungen,
die sich bei zwei Genorten ergeben, analytisch nicht lösen können.
Trotzdem kämpften wir eine Zeitlang mit diesem Problem. Endlich machte
Hans-Michael Voigt den Vorschlag zu überlegen, ob es nicht ein
Rekombinationsverfahren gibt, welches die Gene im Hardy-Weinberg
Gleichgewicht hält.
Die Lösung hatten wir sofort. Alle Gene der selektierten Eltern
werden in
eine Lostrommel gegeben. Aus dieser Lostrommel werden für jeden Genort
die
Gene für jeden Nachkommen zufällig gezogen. So ergibt sich eine
Binomialverteilung. Das Rekombinationsverfahren haben wir Gen Pool
Rekombination genannt. Dieses Verfahren ist mathematisch einfacher zu
analysieren und führt in vielen Fällen sogar schneller zum Ziel.
Die Jungen Wilden
Bis jetzt bin ich auf die Entwicklung der genetischen Algorithmen nicht
eingegangen. Der Grund wird sehr bald deutlich werden. Nach meiner
Spurensuche wurde der erste genetische Algorithmus von Alan Fraser und
Alan Robertson noch vor 1957 implementiert. Dieser Algorithmus wurde
ausschließlich zur Untersuchung populationsgenetischer Fragestellungen
eingesetzt.
Die Idee, genetische Algorithmen für mathematische
Optimierungsaufgaben zu verwenden, stammt von John Holland. Obwohl
Hollands Algorithmus eindeutig eine Implementierung von Mendels
Vererbungsmodell ist, schaute Holland nicht in der Populationsgenetik
nach. Leider entwickelte er eine eigene "Theorie" - wie ich meine, aus
Unkenntnis. Bei geeigneter, falscher Interpretation zeigte seine
Theorie sogar, daß der genetische Algorithmus ein optimaler
Suchalgorithmus ist. Damit bestand für die Forscher natürlich kein
Bedarf, die Theorie weiterzuentwickeln.
Holland war schon bald nicht mehr an Optimierungsproblemen
interessiert, sondern an dem allgemeineren Problem des induktiven
Lernens. Trotzdem entwickelte sich von 1975 bis 1987 unter seiner
Führung eine Michigan Schule der genetischen Algorithmen mit eigener
Geheimsprache. Erst 1989 kam der erste Kontakt mit europäischen
Forschern zustande.
Von 1989 bis heute fand ein oft eher emotional als wissenschaftlich
geführter Theorienstreit statt. Dies ist eine Bestätigung von Darwins
Zyklus-Hypothese auf dem Gebiet des Wettstreites von Ideen. Beim
Aufeinandertreffen von zwei Kontinenten findet ein harter Wettbewerb
statt
zwischen den unterschiedlichen Ideen, die sich innerhalb der Kontinente
entwickelt haben. Für mich günstig hat die Holland Schule sehr lange an
ihrer fehlerhaften Theorie festgehalten. Das hat sich 1994 geändert.
Die
Gleichung für den Selektionserfolg wird nun fast überall zum
Ausgangspunkt einer "neuen" Theorie genommen.
Nachdem die Grundfeste der Holland Schule, das "Schema Theorem",
gefallen ist, befindet sich das Gebiet genetische Algorithmen im
Zustand des Chaos. Leider ist weiter zu beobachten, daß speziell die
jungen Forscher die Populationsgenetik nicht durcharbeiten. Der
triviale Fortschrittsglaube in der Informatik hat bei vielen jungen
Forschern zu der Auffassung geführt, daß das Lesen von alten Artikeln
eine Zeitverschwendung ist, getreu dem Motto: "Alles was älter als zwei
Jahre ist, gehört in den Papierkorb." Der durchschnittliche
Wissensstand auf dem Gebiet der genetischen Algorithmen ist heute
vergleichbar dem Stand der Vererbungsforschung von 1880.
Aufgrund der Vorarbeiten der klassischen Populationsgenetiker wird
sich diese Situation sehr schnell ändern. Man wird nicht noch einmal
100 Jahre zum Verständnis der Entwicklung genetischer Populationen
benötigen. Zur Zeit akzeptieren die jungen Forscher es allerdings noch
nicht, daß viele der theoretischen Probleme, die sie behandeln, schon
einmal gelöst worden sind.
Romantische Wissenschaft
Die mathematische Populationsgenetik hat eine wichtige Rolle beim
Verständnis der Evolution gespielt. Sie wird eine ebenso wichtige Rolle
bei der Entwicklung einer Theorie genetischer Algorithmen spielen.
Allerdings
ist es ein Mißverständnis zu glauben, daß die mathematische
Populationsgenetik die Theorie der Evolution ist. Der Grund liegt in
der
Geschichtlichkeit und Einmaligkeit jedes Lebewesens. Konrad Lorenz
schrieb:
"Alle Lebewesen sind historische Wesen und ein wirkliches Verstehen
ihres
So-Seins ist grundsätzlich nur auf der Grundlage eines historischen
Verstehens jenes einmaligen Entwicklungsvorganges möglich."
Die Geschichtlichkeit ist der Grund dafür, daß viele realistische
populationsgenetische Modelle, abhängig von den Anfangsbedingungen,
eine Vielzahl von unterschiedlichen Lösungen haben. Selbst die so
harmlos aussehende Populationsgleichung
P(t+1) = kP(t)(1-P(t))
ist ein Mitglied der Feigenbaum Gleichungen und zeigt Bifurkationen
und chaotisches Verhalten für k>=3. P ist eine Zahl zwischen 0 und 1
und repräsentiert die Größe der Population dividiert durch eine
theoretische Maximalgröße.
Trotz dieses prinzipiellen Problems ist immer wieder die Gefahr
eines biologischen Determinismus zu beobachten. Diesen Determinismus
hat der Evolutionsbiologe Stephen Jay Gould in einer Reihe von Büchern
eindrucksvoll angeprangert. "Webs and chains of historical events are
so intricate, so imbued with random chaotic elements, so unrepeatable
that standard models of simple prediction do not apply. The actual
pathway is strongly underdetermined by our general theory of life's
evolution." Besonders erwähnt Gould folgende Gefahr: "The mystique of
science proclaims that numbers are the ultimate test of objectivity.
...But I have continually located a priori prejudice, leading
scientists to invalid conclusions from adequate data, or distorting the
gathering of data itself."
Statt mehr Zahlen braucht die Biologie wieder etwas mehr Romantik.
Dieser Begriff ist von Max Verworn zu Beginn dieses Jahrhunderts
eingeführt worden. Verworn schrieb, Wissenschaftler ließen sich in zwei
Schulen einteilen: die klassische und die romantische. Der klassische
Wissenschaftler zerlegt Ereignisse in ihre Bestandteile. Schritt für
Schritt nimmt er sich wesentliche Einheiten und Elemente vor, bis er
schließlich allgemeine Gesetze formulieren kann. Diese Methode
reduziert die lebendige Wirklichkeit in ihrer reichen Vielfalt zu
abstrakten Schemata.
Der romantische Wissenschaftler läßt sich von genau den
entgegengesetzten Interessen und Vorgehensweisen leiten. Seine
Hauptaufgabe sieht er darin, den Reichtum der Lebenswelt zu bewahren,
und er erstrebt eine Wissenschaft, die sich dieses Reichtums annimmt.
Leider ist die romantische Wissenschaft durch die großen Erfolge der
klassischen Wissenschaft fast ausgestorben.
Klassische und romantische Wissenschaft sind keine Gegensätze. Schon
gegen Ende des vergangenen Jahrhunderts beobachtete der Psychologe
William James den Übergang zu einem trockenen and armseligen
Reduktionismus. Er sprach die Hoffnung aus: "Eines Tages werden unsere
Nachfahren mit all unseren analytischen Untersuchungen im Kopf die
Natur anders und mit mehr Feingefühl betrachten, als es irgendeinem
Forscher aus der Generation von Darwin oder Agassiz möglich war."
Diese Prophezeiung ist leider noch nicht eingetreten. Die Anwendung
und die
Analyse genetischer Algorithmen kann durchaus zu mehr Feingefühl bei
der
Betrachtung der Natur führen. Die Algorithmen selber sind eine Methode
der
klassischen Wissenschaft und müssen mit der klassischen Technik
analysiert
werden. Dagegen ist es höchste Zeit, daß die Biologie wieder
romantischer wird. Große Sorge bereitet mir, daß offensichtlich genau
das Umgekehrte passiert. Mit der neuen Mode "Artificial Life" wird die
Wissenschaft bei einem künstlichen System romantisch, besser gesagt
esoterisch.
heinz.muehlenbein@online.de
 |
Genetische Algorithmen: Transport-Optimierung und
Tourenplanung für ein zentrales Auslieferungsdepot
|
Von Andreas Reinholz
Aufgrund der verschärften Konkurrenz unter den
Transportunternehmen
durch die Öffnung des europäischen Binnenmarktes und die immer größer
werdende Beachtung von Umweltaspekten, gewinnen Verfahren zur Lösung
von Problemen aus dem Bereich der Transportoptimierung und
Tourenplanung zunehmend an Bedeutung. Im folgenden Beitrag wird eine
konkrete Problemstellung aus dem Bereich der Transportoptimierung
beschrieben, die in Zusammenarbeit mit einem Partner aus der Wirtschaft
erarbeitet worden ist. Ziel der Optimierung ist ein Tourenplan für
einen Fuhrpark, mit dem Großkunden von einem zentralen
Auslieferungslager über einen Planungshorizont von einer Arbeitswoche
möglichst kostengünstig beliefert werden können. Die aufgeführte
Problemstellung ist eine Erweiterung des klassischen Single Depot
Problems, da hier zusätzlich mehrfache Kundenbesuche innerhalb des
Planungshorizontes berücksichtigt werden. In diesem Beitrag liegt das
Schwergewicht zunächst auf der Problembeschreibung und Modellbildung.
Anschließend werden die Problemstruktur analysiert und ein
Lösungsansatz mittels eines problemspezifischen Genetischen Algorithmus
skizziert.
In der GMD-Arbeitsgruppe Adaptive Systeme wird eine rechnergestützte
Lösung mittels Genetischer Algorithmen für ein
Transportoptimierungsproblem erarbeitet, dem eine konkrete
Aufgabenstellung der siegerländischen Firma BUB zugrunde liegt. Die
Firma BUB ist als Industrievertretung von Duscholux, einem führenden
Hersteller aus dem Sanitärbereich, für die Organisation und Abwicklung
des Werksverkehrs innerhalb ihres Handelsgebietes zuständig. Ausgehend
von ihrem Zentrallager in Siegen beliefert sie rund 250 Großhändler in
ganz Nordrhein-Westfahlen bis zu dreimal pro Woche mit Waren
unterschiedlicher Größe (siehe Abbildung 1).
Problembeschreibung
Innerhalb eines Planungshorizontes von einer Arbeitswoche (Montag bis
Freitag) müssen die Großkunden mit täglichen Rundtouren von dem
Zentrallager aus unter bestimmten Nebenbedingungen bedient werden:
- Die eingesetzten Fahrzeuge müssen nach jeder Tour zum
Zentrallager zurückkehren.
- Jedes Fahrzeug wird höchstens einmal pro Tag eingesetzt, da es am
Vorabend beladen wird.
- Die Dauer jeder Tour ist durch die maximale Arbeitszeit der
Fahrer beschränkt, das Frachtvolumen pro Tour durch die maximale
Kapazität der Fahrzeuge.
- Vorgegebene Besuchshäufigkeiten, die vom Umsatz des Kunden
abhängen, sind einzuhalten (Servicebedingung).
- Jeder Kunde darf höchstens einmal pro Tag angefahren werden. Die
Besuche bei Kunden, die innerhalb einer Arbeitswoche mehrfach beliefert
werden, sind geeignet zu verteilen, um eine zeitliche Entzerrung zu
gewährleisten.
- Die gesamte Fracht wird zugestellt.
Ziel der Optimierung ist das Erzeugen eines Wochenplanes, der alle
aufgeführten Nebenbedingungen erfüllt und dessen Ausführung möglichst
geringe Kosten verursacht. Dabei wird eine Kostenfunktion verwendet,
die im wesentlichen von der Anzahl und Gesamteinsatzzeit der
verwendeten Fahrzeuge abhängt. In der Einsatzzeit der Fahrzeuge werden
dabei neben der reinen Fahrzeit auch die Entladezeiten bei den Kunden
berücksichtigt.

Modellierung
In mehreren Besprechungen mit Vertretern der Firma BUB wurde das
beschriebene ZAD-Problem (Zentrales Auslieferungsdepot) analysiert.
Dabei wurde ein rechnergestütztes System für die Problemlösung
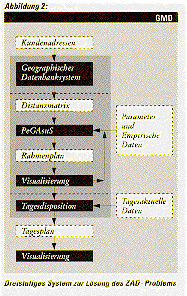
konzipiert, das aus drei Komponenten besteht (siehe auch Abbildung 2).
Die erste Komponente bekommt als Eingabe eine Kundenliste, berechnet
mit Hilfe einer geographischen Datenbank die Fahrzeiten zwischen den
Kunden und speichert sie in einer Zeit-Enfernungsmatrix ab
(Problemstellungskomponente). Das Depot
wird hierbei als Kunde mit der Kundennummer Null berücksichtigt. Das
Erstellen der Entfernungsmatrix, die wesentlich für die Kostenfunktion
ist, muß maschinell erfolgen, da bei 250 Kunden insgesamt 31375
Fahrzeiten zu bestimmen sind.
Die zweite Komponente enthält das eigentliche Optimierungsproblem,
bei dem der Genetische Algorithmus zum Einsatz kommt. Aufgrund
statistischer Daten aus der Vergangenheit soll ein Rahmentourenplan für
eine Arbeitswoche erzeugt werden. Hierzu wird der Parallele Genetische
Algorithmus Simulator PeGAsuS verwendet, der in der Forschungsgruppe
Adaptive Systeme entwickelt wurde. PeGAsuS liefert hierbei einen
Basisalgorithmus, in den problemspezifi-sche Operatoren und lokale
Optimierungsverfahren zu integrieren sind (siehe Abbildung 4). Ein so
gewonnener optimierter Rahmenplan soll sicherstellen, daß die
geforderten Besuchshäufigkeiten eingehalten werden (Servicebedingung),
und daß die durchschnittlichen Frachtaufkommen der Kunden kostengünstig
zustellbar sind.
Die dritte, sogenannte dispositive Komponente geht von dem auf
statistischen Daten basierenden Rahmenplan aus und sorgt dafür, daß ein
zu fahrender Tagesplan an die konkret auszuliefernden Frachtvolumina
angepaßt wird. Dabei werden auch Sonderlieferungen durch zusätzliche
Lastkraftwagen berücksichtigt.
Kostenfunktion
Eine große Bedeutung bei der Modellbildung hat die Erstellung der
Fitneß- beziehungsweise Kostenfunktion, da die Genetischen Algorithmen
zu den Optimierungsverfahren gehören, deren Suche durch eine solche
Funktion gesteuert wird.
In die Kostenfunktion gehen im wesentlichen die Zeit für die
gefahrenen Strecken und die individuelle Ladezeit beim Kunden ein.
Dabei ergeben sich die Gesamtkosten einer Lösung des ZAD-Problems
(Wochenplan) aus der Summe der Kosten aller Tagespläne. Die Kosten für
einen Tagesplan berechnen sich wiederum aus der Summe der Kosten aller
enthaltener Touren. Die Kosten für eine Tour setzen sich zusammen aus
der Tourlänge und zusätzlichen Kosten für Verletzungen der
Nebenbedingungen (Zeit- und Frachtbedingung).
Für ein Überschreiten der Zeitschranke wird in zwei Stufen ein
Kostenterm addiert. Wird die normale Arbeitszeit des Fahrers
überschritten, so wird ein Überstundenzuschlag berechnet. Ist darüber
hinaus die Fahrzeit größer als die maximale Arbeitszeit des Fahrers,
werden die Kosten für die Tour so angesetzt, als ob mehrere Touren
gefahren würden, welche die Nebenbedingungen einhalten.
Bei der Kapazitätsbeschränkung der Fahrzeuge wird ähnlich
vorgegangen. Die angegebene Frachtkapazität hat eine Sicherheitsmarge
von ungefähr zehn Prozent. Diese Sicherheitsmarge soll dazu dienen,
statistische Schwankungen des Frachtaufkommens abzufangen.
Überschreitungen der Kapazität in diesem Rahmen werden moderat mit
geringen zusätzlichen Kosten bewertet. Darüber hinausgehende
Überschreitungen werden wiederum so behandelt, als ob mehrere Touren
gefahren würden, welche die Nebenbedingungen einhalten.
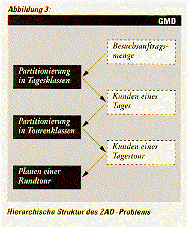
Problemhierarchie
Eine vielversprechende Methode für die Bearbeitung komplexer Probleme
ist die Unterteilung des Gesamtproblems in eine Hierarchie von
einfacher zu lösenden Teilproblemen.
In dem ZAD-Problem sind das Travelling Salesman Problem, das Single
Depot
Problem, und ein Partitionierungsproblem mit zusätzlichen
Randbedingungen
in Form einer Problemhierarchie enthalten.
Partitionierungsproblem
Aus der Kundenliste wird eine Besuchsauftragsmenge gebildet, bei der
die Kunden entsprechend ihrer Besuchshäufigkeit berücksichtigt werden.
Eine Lösung des ZAD-Problems unterteilt die Menge der Besuchsaufträge
in disjunkte Teilmengen, deren Kunden durch jeweils einen Tagesplan zu
bedienen sind (Tagesklassen). Die Bewertung jeder dieser Tagesklassen
wird durch den jeweils besten Tagestourenplan festgelegt. Dadurch wird
ein Partitionierungsproblem auf der Menge der Besuchsaufträge
definiert, bei dem zusätzliche Nebenbedingungen, zum Beispiel die
Servicebedingung, beachtet werden müssen. Das Bestimmen der jeweils
optimalen Tagestourenpläne entspricht dann dem klassischen Single Depot
Problem ohne Time Windows.
Single Depot Problem
Dieses Single Depot Problem kann wiederum als ein
Partitionierungsproblem beschrieben werden. Hierbei sind die Kunden
einer Tagespartition in disjunkte Teilmengen (Tourenklassen) zu
unterteilen, die jeweils von einem Lastkraftwagen in einer Rundtour
bedient werden.
Travelling Salesman Problem
Die Bewertung jeder Tourenklasse erfolgt über die jeweils beste
Rundtour durch alle Kunden dieser Teilmenge. Dieses Teilproblem ist das
klassische symmetrische Travelling Salesman Problem.
Lösungsansatz
Für das Travelling Salesman Problem und das Single Depot Problem
konnten schon effiziente und leistungsfähige Genetische Algorithmen
entwickelt werden. Die besonderen Schwierigkeiten beim ZAD-Problem
ergeben sich aus den zusätzlichen Randbedingungen der obersten
Hierarchieebene. Darüber hinaus ist die Problemhierarchie so gestaltet,
daß sich die Komplexitäten aller drei Probleme multiplizieren.

Problemspezifische Operatoren
Die Unterteilung des ZAD-Problems in diese Hierarchie von Teilproblemen
ermöglicht die Entwicklung von Operatoren, die zielgerichtet auf den
einzelnen Ebenen der Problemhierarchie arbeiten und dabei
problemspezifische
Information ausnutzen. Daher wird hier ein Genetischer Algorithmus zur
Lösung des ZAD-Problems erarbeitet über die Entwicklung und Integration
von Lösungsansätzen für
- das Travelling Salesman Problem,
- das Single Depot Problem und
- das Partitionierungsproblem.
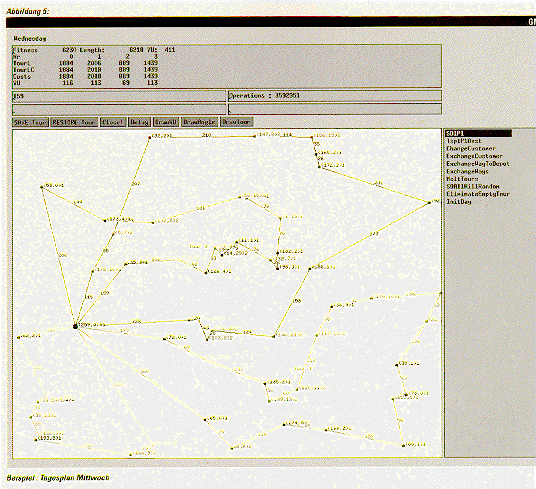
Visualisierung
Bei der Entwicklung leistungsfähiger Optimierungsverfahren für das
ZAD-Problem wird besonderer Wert auf die Implementierung eines
Visualisierungstools gelegt, mit dem eine konkrete Suche animiert und
gefundene Problemlösungen grafisch dargestellt werden können. Ein
geschulter Beobachter hat eine intuitive Vorstellung davon, wie gute
Problemlösungen aussehen, und kann häufig erkennen, wo
Problemlösungen ihre Schwachstellen haben.
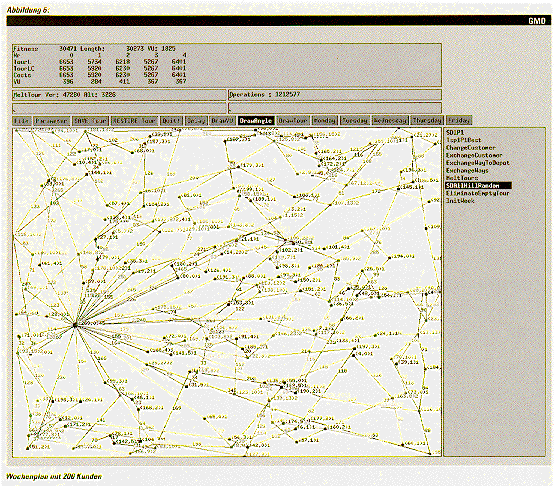
Daher kann die Visualisierung
für die Beurteilung der Leistungsfähigkeit von Operatoren und die
Aufdeckung synergetischer Wirkungen verwendet werden. Darüber hinaus
ist
die Visualisierung wichtig als optische Kontrolle für eine korrekte
Implementierung der Operatoren. Das Visualisierungstool wird auf zwei
Plattformen realisiert:
- Auf IBM-kompatiblen Personal Computern unter der Umgebung
DOS/Windows. Die derzeitige Rechnerausstattung des Industriepartners
besteht aus einem Netzwerk dieser Rechner. Ein Visualisierungstool ist
auf dieser Plattform notwendig, damit zum Beispiel manuelle
Verbesserungen oder kurzfristige Änderungen berücksichtigt werden
können. Hierdurch können unter anderem Erfahrungen des
Industriepartners eingebracht werden, die in dem mathematischen Modell
dieses Optimierungsproblems nicht erfaßt sind.
- Die zweite Rechnerplattform sind UNIX Workstations mit der
Grafikumgebung X Window System. Die UNIX Workstations dienen hierbei
als Frontend zu leistungsfähigen Rechnern und Netzwerken. Hiermit kann
zum Beispiel die Rechenleistung von Parallelrechnern für die
Bearbeitung größerer Probleme genutzt werden. Das fertige System wird
als Pilotanwendung bei der Duscholux Industrievertretung BUB verfeinert
und getestet.
Erweiterungsmöglichkeiten
Die vorgestellte Aufgabenstellung, bei der von einem zentralen
Auslieferungslager Kunden unter zusätzlichen Randbedingungen zu
bedienen sind, kommt in der Wirtschaft häufig vor. Daher ist das hier
beschriebene System zur Lösung des ZAD-Problems so konzipiert, daß es
an veränderte Nebenbedingungen angepaßt werden kann.

 |
Reflexion - die Entwicklung einer Idee
|
Von Uwe Beyer und Frank Smieja
In dem Maße, in dem Software sich im täglichen Leben verbreitet,
versucht sie auch Eingang in wenig strukturierte Anwendungen zu finden.
In solchen Bereichen können die Probleme nicht mehr an die Software
angepaßt werden, vielmehr muß sich die Software an das Problem
adaptieren. Da ein solcher Anpassungsprozeß sehr umfangreich sein kann
und im praktischen Einsatz kaum vorhersagbar ist, gewinnt der Aspekt
der Selbst-Anpassung von Software bei der Erschließung neuer
Anwendungsbereiche zunehmend an Bedeutung. Durch die Anwendung
adaptiver Methoden erwirbt das System Wissen über die reale Welt. Eine
der subtilen Eigenschaften solchen Wissens besteht in seiner
Unvollständigkeit und in einer nicht vermeidbaren Unsicherheit über
seine Anwendbarkeit bei konkreten Aufgaben. Um technische Systeme zu
bauen, die damit fertig werden, müssen auch Konzepte zur Behandlung von
Unsicherheit und Unvollständigkeit vorhanden sein, die ein Reflektieren
über das eigene Wissen gestatten.
Im GMD-Spiegel 2/91 erschien im Juni 1991 ein Artikel mit dem Titel
"Reflektive neuronale Netzwerkarchitekturen". In diesem Aufsatz wurden
einige Ideen skizziert, die einerseits einfach und offensichtlich
waren, andererseits einen großen Horizont an Möglichkeiten aufzeigten.
In den letzten vier Jahren wurden in REFLEX die technischen und
konzeptionellen Möglichkeiten der 1991 beschriebenen Ideen von Adaption
und Reflexion systematisch untersucht. Im folgenden Beitrag möchten wir
entlang der Entwicklungsgeschichte von REFLEX die entstandenen Konzepte
und Ideen schrittweise vorstellen. Hierbei sehen wir wissenschaftliche
Arbeit nicht als Präsentation von historielosen Ergebnissen, sondern
als eine inkrementelle Entwicklung von Ideen. Sinn dieses Textes soll
nicht das Darstellen von fertigen Detaillösungen sein (die man
natürlich in unseren Veröffentlichungen nachlesen kann), sondern wir
möchten einen Überblick über die "grundsätzliche Marschrichtung"
unserer Forschung geben.
Der Startpunkt aller Überlegungen: "Reflexion"
Ausgangs- und Kernpunkt aller unserer Arbeiten sind adaptive Systeme,
die aus "lernenden Einheiten" bestehen. Diese Einheiten lernen eine
Abbildung von einem Definitionsbereich D in einen korrespondierenden
Wertebereich W anhand von Beispiel-Tupeln der Abbildung. Die erlernte
Abbildung kann verwendet werden, um auch y e W Werte für solche x e D
Werte vorherzusagen, die nicht in der Beispielmenge waren (siehe
Abbildung 1). Die zu erlernenden Abbildungen sind in der Regel
kontinuierlich. Im Gegensatz zur klassischen Künstlichen Intelligenz,
in der das Modell der Abbildung mittels Regeln in meist diskreten
Räumen (häufig durch Prädikatenlogik) beschrieben wird, verwenden wir
für unsere adaptiven Einheiten solche Methoden, wie sie aus dem Gebiet
der neuronalen Netze beziehungsweise der Theorie der
Funktions-Approximation bekannt sind.Ein beliebtes Experimentierfeld
für solche Methoden stellt die automatische Erkennung von
handgeschriebenen Buchstaben (Optical Character Recognition) dar.
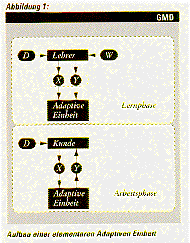
Während der Lernphase, wird dem System eine Menge von "gescannten"
Buchstaben gezeigt. Zusätzlich wird mitgeteilt, um welche Buchstaben es
sich handelt. In der anschließenden Arbeitsphase soll das System die
Klassifikation von weiteren noch nicht gesehenen (aber natürlich
relativ ähnlichen) Buchstaben sicher ausführen können.
Solche Systeme werden weltweit untersucht und haben mittlerweile
auch eine begrenzte Marktreife erreicht. Die wesentlichen Ideen des
REFLEX- Projektes starteten mit dem Erkennen eines folgenschweren
Mangels solcher Systeme: Das System reflektiert nicht, wie sicher sein
Wissen ist. Eines der Hauptprobleme von lernenden Systemen ist, daß sie
keine "Vorstellung" davon haben, was sie nicht können.
Wenn einem OCR-System (Optical Character Recognition) ein Buchstabe
gezeigt wird, dessen eindeutige Klassifizierung nicht möglich ist, so
wird sich das System für die nach seiner Meinung beste Klassifikation
entscheiden und diese als Antwort geben. Für den externen Rezepienten
der Antwort ist aber nicht erkennbar, daß die gegebene Antwort
"unsicher" ist. Insbesondere würde ein "Kinderkrakel" vom System mit
dem "Brustton der Überzeugung" als irgendein Buchstabe klassifiziert.
Ein solches Verhalten ist offensichtlich unsinnig und kann
hochgradig gefährlich sein. Auf jeden Fall ist ein sicheres Team-Work
zwischen einem nicht reflektierenden System und weiteren Instanzen in
kritischen Situationen extrem fehleranfällig. Hieraus leitet sich eine
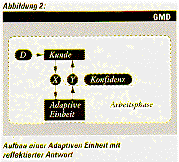
neue Anforderung für adaptive Systeme ab: Adaptive Systeme müssen über
ihre Fähigkeiten reflektieren.
In den von uns untersuchten reflektiven adaptiven Systemen wird dies
durch eine Erweiterung der Antwort erreicht. Zusätzlich zum y-Wert
liefert eine reflektive Einheit eine Meta-Information (zum Beispiel
eine Konfidenz-Abschätzung), die eine Beurteilung der Qualität der
Antwort enthält (siehe Abbildung 2). Diese Qualitätsabschätzung muß
ebenfalls von der adaptiven Einheit erlernt werden.
Erste Versuche mit Reflexion
Nachdem die Notwendigkeit der Reflexion erkannt ist, ergibt sich eine
Vielzahl weiterer Detail-Fragen, zu deren Beantwortung wir OCR als
Experimentierfeld herangezogen haben. Solche Fragestellungen sind :
- Wie kann die Konfidenzeinschätzung erlernt werden?
- Ist eine mathematisch korrekte Herleitung von Konfidenz, etwa als
Wahrscheinlichkeit, denkbar ?
- Ist eine allgemeine Definition der Semantik von Konfidenz
möglich?
Die Beantwortung dieser Fragen ist extrem schwierig und kann zum
jetzigen
Zeitpunkt nicht abschließend geleistet werden. Die Frage wird
ausführlicher in dem Aufsatz "Konstruktive Datenerhebung mit
reflektiven neuronalen Netzen" von Jörg Kindermann und Gerhard Paaß
in diesem Heft diskutiert. Neben diesen unmittelbar mit der Reflexion
gekoppelten Fragen ergibt sich eine Menge von technischen Möglichkeiten
durch den Einsatz von Konfidenz. Unter anderem kann sie dazu verwendet
werden, um den adaptiven Einheiten eine aktive Exploration der
Abbildung zu
ermöglichen.
Hierzu kann die Einheit aktiv einen x-Wert auswählen, zu dem es mit
seinem derzeitigen Wissen nur eine Antwort mit niedriger Konfidenz
geben könnte. Es kann nun gezielt nach dem korrespondierenden y-Wert
fragen, um so eine gute Verbesserung seines Wissens zu erzielen. Trotz
der schwierigen theoretischen Beherrschbarkeit von Reflexion hat diese
im Experiment ihre Leistungsfähigkeit für technische Lösungen eindeutig
bestätigt.
Reflexion der Schlüssel zum Team-Work
Ende der Entwicklung? Nein, während der OCR-Experimente sind einige
Eigenschaften der grundsätzlichen Struktur von Definitions- und
Wertebereichen der zu erlernenden Abbildungen aufgefallen. Aus Sicht
der adaptiven Einheiten scheint es zwei Klassen von Problemen zu geben.
ĐĘProbleme in artifiziellen Welten. Häufig werden die Eigenschaften
von
adaptivem Verhalten in kleinen abgeschlossenen, vollkommen künstlichen
Welten auf dem Rechner untersucht. Der Versuch trägt den Charakter
eines Gedanken-Experiments.
ĐĘProbleme aus der "echten Welt". Im Gegensatz zur obigen
Vorgehensweise besteht auch die Möglichkeit, Daten aus der "echten
Welt" zu benutzen. Das Erkennen von menschengeschriebenen Buchstaben
gehört in diese Klasse.
Empirische Erfahrungen zeigen, daß die "echte Welt" auf eine aus
mathematischer Sicht sehr subtile Weise verschieden von den künstlichen
Welten ist. In den künstlichen Umgebungen kann in aller Regel perfekt
adaptiert werden, das heißt, nach einer plausibel langen Lernphase
verhalten sich die adaptiven Einheiten fast perfekt. Das Verhältnis von
Lern-Aufwand zu Verhaltensverbesserung stimmt. Das liegt nicht zuletzt
daran,
daß der Experimentator diese Welten perfekt kennt und seine
Adaptionsverfahren bewußt oder unbewußt so wählt, daß sie optimal
zu den Problemen passen.
In "echten Welten" bleibt in der Regel jedoch eine
Rest-Approximationsunschärfe, das heißt, das Verhalten kann durch
Lernen nicht beliebig verbessert werden, es bleiben die "verflixten
letzten fünf Prozent", die mit vertretbarem Aufwand nicht erlernt
werden können. Oberhalb dieser Grenze ist jede noch so kleine
Verbesserung extrem viel teuerer als alles Lernen vorher. Andererseits
ist es recht erstaunlich zu sehen, was für eine Vielzahl von teilweise
recht "dummen" Verfahren in der Lage ist, die ersten "95 Prozent" zu
erlernen.
Obwohl uns diese Grenze empirisch als unüberwindbar erscheint, gibt
es doch einige "Tricks" um trotzdem eine weitere Verbesserung des
Systemverhaltens erzielen zu können. Hieraus ist eine weitere Kernidee
des REFLEX-Projektes entstanden.
"Wenn verschiedene Mitglieder eines Teams dasselbe Problem
bearbeiten, so finden einige von ihnen bestimmte Teilaspekte des
Gesamtproblems leichter beziehungsweise schwerer als andere Mitglieder
des Teams"
Die Team-Mitglieder ergänzen sich. Die Erfahrung zeigt, daß Teams in
vielen Fällen erfolgreicher sein können, als "Einzelkämpfer". Um eine
plausible Team-Entscheidung erreichen zu können, müssen die Mitglieder
jedoch ihre Stärken und Schwächen kennen und diese auch den anderen
Team-Mitgliedern offenbaren. Hierzu kann wiederum Konfidenz verwendet
werden.
Im Rahmen der OCR-Experimente haben wir diese Idee auf ein Team von
adaptiven Einheiten übertragen. Ab diesem Zeitpunkt haben wir begonnen,
von den adaptiven Einheiten als "Individuen" zu denken, was sich darin
ausdrückt, daß sie in allen unseren folgenden Überlegungen als adaptive
Agenten bezeichnet werden. Das daraus enstandene technische System
sieht wie in Abbildung 3 gezeigt aus.
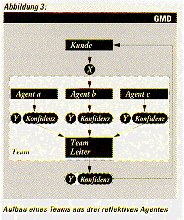
Hierbei wird der zu erkennende Buchstabe mehreren Agenten
gleichzeitig
gezeigt. Jeder dieser Agenten benutzt ein anderes Verfahren, um zu
einer
Klassifikation zu gelangen. Die verschiedenen Klassifikationen und ihre
zugehörigen Konfidenzen werden anschließend von einem Team-Leiter zu
einer Gesamtantwort integriert. So plausibel diese Idee ist, soviele
neue
Fragen wirft sie auf :
- Wie soll die Synthese der Antwort erfolgen?
- Wie gelangen die Agenten zu Konfidenzabschätzungen, die
einenVergleich untereinander ermöglichen?
- Wie sollen Team-Mitglieder beschaffen sein, um optimal in das
Team zu
passen?
Die folgende Untersuchung dieser Fragen dauert immer noch an, und auch
hier erscheint eine abschließende Beantwortung kaum möglich, da eine
Vielzahl von ungeklärten Fragestellungen aus mehreren Bereichen der
Mathematik und Informationstheorie berührt wird. Für konkrete Probleme,
wie unsere OCR-Experimente, funktionieren Teams jedoch zuverlässig. Man
erhält beim Testen einer größeren Menge von Buchstaben, eine
reproduzierbare signifikante Verbesserung des Gesamtfehlers auf der
Testmenge, wenn man ein Team mit seinem besten Mitglied vergleicht.
Ein einzelner Agent kann intern wieder aus einem Team bestehen, das
heißt, Teams erlauben den Aufbau von rekursiven Strukturen. Zusammen
mit der Möglichkeit zur Kaskadierung von Agenten erhält man so einen
"Baukasten" zum Konstruieren komplexer Architekturen von Agenten.
Die architekturellen Aspekte
Wenn man die Gültigkeit der (nur postulierten, und vermutlich auch kaum
beweisbaren) Approximationsunschärfe akzeptiert, so erscheint eine
Fokussierung auf die Verbesserung von Einzelagenten kaum mehr
interressant, wenn diese einmal die "95 Prozent-Grenze" errreicht
haben. Deswegen haben wir unsere weiteren Untersuchungen stark an den
architekturellen Aspekten großer Agenten-Systeme für "echte Welt"
Probleme orientiert.
Dazu haben wir die immer noch relativ statische und abgeschlossene
Umgebung des OCR verlassen und uns der Steuerung von
Roboter-Manipulatoren zugewandt. Bei der Steuerung solcher Systeme ist
eine Vielzahl von Teilproblemen, wie zielgerichtete Armbewegungen,
Kollisionsvermeidung, Planen von Bewegungsbahnen, ... zu lösen. Diese
Aufgaben sind vielfach derart schwierig, daß es für sie keine technisch
umsetzbaren analytisch optimalen Lösungen gibt. Wenn solche Aufgaben
per Adaption erlernt werden sollen, so gilt für sie alle die "echte
Welt"-Eigenschaft.
Das von uns angestrebte System JANUS, soll wie in Abbildung 4
dargestellt
aussehen. Es besteht aus zwei Manipulatoren sowie einem
Bildverarbeitungs-System. Diese Komponenten sind in einer Arbeitszelle
montiert. In dieser Umgebung soll das System durch Interaktion mit
einem
Menschen in mittelstark strukturierten Alltagsszenen (Labor,
Schreibtisch)
motorische Aufträge (Greifen, Bewegen, ...) ausführen können. Das
System soll das hierfür erforderliche Wissen zur Steuerung der
Manipulatoren sowie zur Planung der Bewegungen inkrementell und autonom
erlernen. Es soll in der Lage sein, solches Wissen von einer Aufgabe
auf eine
ähnliche andere Aufgabe zu übertragen, ohne viel neu lernen zu
müssen.

Die Implementation des Systems erfolgt schrittweise, erst als
Simulation,
dann unter Verwendung von "echten" Manipulatoren und Kameras. Zur Zeit
ist
die gewünschte Funktionalität in der Simulation vorhanden, und wir
beginnen mit der Verwendung der realen Manipulatoren. (Unter http://www.ais.fraunhofer.de/AS/janus/pages/janus.html
kann per World Wide Web ein Beispiel-Film abgerufen werden, der einen
Eindruck der Simulation vermittelt.)
Der Schritt zum "echten" Manipulator ist zwar technisch sehr
aufwendig, er ist jedoch aus Sicht unserer Ideen essentiell notwendig,
da wir gerade postuliert haben, daß sich "echte Welt"-Effekte nicht
simulieren lassen.
Im Gegensatz zu OCR, wo alle Agenten auf ein gemeinsames Ziel
zuarbeiten (der Klassifikation des Buchstaben) existiert in JANUS eine
Vielzahl von teilweise konträren Zielsetzungen (siehe Abbildung 5).
So steht zum Beispiel der Wunsch, eine Kollision zu vermeiden,
eventuell im Widerspruch zu dem Wunsch, einen bestimmten Gegenstand zu
greifen, wenn dies nur dann möglich ist, wenn man sehr nahe an anderen
Gegenständen vorbeigreift. Hieraus ensteht eine weitere wesentliche
Forderung an ein komplexes adaptives System: "Das System muß auch bei
widerstrebenden Teilzielen ein sinnvolles und zielgerichtetes
Gesamtverhalten produzieren können. Es muß widersprüchliche
Informationen verarbeiten können."
Ein weiterer wesentlicher Unterschied zu OCR besteht darin, daß ein
System mit Manipulatoren die Welt aktiv verändern kann. Diese
Veränderungen haben dann eventuell in hochgradig nichtlinearer Weise
Einfluß auf die Zukunft des Systems selber. Die Welt und das System
sind durch die Physik derart stark rückgekoppelt, daß es sinnvoll ist,
sie konzeptionell als eine Einheit zu sehen. Dieser Effekt ist durch
seine hohe Eigendynamik für "offene Welt"-Anwendungen durchaus genauso
wichtig, wie es das Neuman-Konzept für die moderene
Informationsverarbeitung ist.

Um in einer solchen Umgebung die Idee von Adaption untersuchen zu
können, muß die Welt auf eine sehr aktive Weise in die Modellbildung
des Systems einbezogen werden. Die Suche nach derartigen Modellen ist
einer der wesentlichen wissenschaftlichen Kernpunkte des
REFLEX-Projektes geworden. In diesem Zusammenhang erscheint das
Phänomen der Approximationsunschärfe als Sonderfall eines wesentlich
allgemeineren Phänomens von grundsätzlicher Unsicherheit, wie sie zum
Beispiel von Karl R. Popper auf philosophischer Ebene beschrieben wird.
Um eine Interaktion mit einem Menschen sicher ausführen zu können,
muß das Gesamtsystem rudimentäre Sicherheitszusagen, wie zum Beispiel
die Vermeidung der Kollisionen, immer garantieren. Hierdurch ergeben
sich weitere Anforderungen, wie etwa Realzeitfähigkeit und die
Notwendigkeit, reflexartig reagieren zu können. Beide Forderungen
stehen im Gegensatz zu Eigenschaften vieler heute untersuchter
Adaptionsmethoden, die häufig relativ langsam lernen und normalerweise
große Probleme haben, bestimmte Grenzen "scharf" einzuhalten.
Bei der Implementierung der Steuerung von JANUS wurde
offensichtlich, daß eine (wie in Abbildung 3 gezeigte) feste
Konnektivität zwischen den Agenten zu unflexibel ist, um mit einem
System von stark widersprüchlichen und unvorhersagbaren Informationen
adäquat umzugehen, da in einem solchen System alle möglichen
Interaktionen von Agenten zu Beginn "fest verdrahtet" werden müssen.
Dieses Problem wird durch die Einführung einer dynamischen
Konnektivität gelöst.
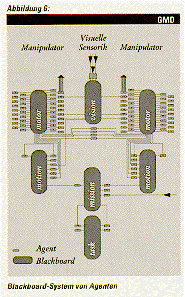
Die Agenten des JANUS-Systems sind um zentrale Informations-Speicher
(blackboards) angeordnet. Auf diesen Speichern befinden sich typisierte
Informations-Behälter (tags). Jeder Agent kann nach seinen eigenen
Notwendigkeiten, Informationen lesen, beziehungsweise seine Ergebnisse
als neue Informationen auf die Speicher schreiben. Die Informationen im
Speicher veralten, so daß jeweils nur die aktuell interressante
Information vorhanden ist.
Die Agenten agieren natürlich nicht wahllos, sonderen versuchen
durch
gruppenweise Zusammenarbeit, Gruppen von Funktionalitäten zu
garantieren,
wie sie in Abbildung 5 gezeigt sind.
In JANUS werden mehrere Blackboards verwendet. Diese Blackboards
sind untereinander durch Agenten verbunden, die auf mehreren Boards
gleichzeitig agieren können. Während der Laufzeit von JANUS können
Agenten erzeugt beziehungsweise gelöscht werden, wenn dies erforderlich
ist. Abbildung 6 zeigt eine typische Agenten-Konfiguration von JANUS.
Aufgrund der Vielzahl von Agenten und Tag-Typen kann hier keine
genaue Beschreibung der Funktionalität gegeben werden, Abbildung 7
enthält aber einige Beispiele, die vielleicht eine Idee davon
vermitteln, auf welcher Ebene die Agenten arbeiten.
Adaption und Architektur
Durch den Aufbau komplexer Strukturen von Agenten ergeben sich neue
Aspekte
bei der Betrachtung von Adaption. Sie ist auf vielen Ebenen und in
vielen
Varianten möglich. Um bei der extremen Vielzahl von Möglichkeiten
überhaupt zu einer systematischen Betrachtung von Adaption zu gelangen,
haben wir Ebenen von Adaption unterschieden.
- Adaption innerhalb von Agenten
Jeder Agent kann eine adaptive Einheit sein, die wie oben
beschrieben eine lokale Optimierung des eigenen Verhaltens durchführt.
Die hier verwendeten Mechanismen sind unter anderem Hauptgegenstand der
Forschung im Bereich Neuronaler Netze. Die hiermit verbundene
Bestimmung der Konfidenzen ist eine neue Fragestellung im Bereich
aktueller Arbeiten der Statistik.
- Adaption innerhalb eines Teams
Der Team-Leiter kann die Art der Erzeugung von Team-Antworten
adaptiv ändern. Rein formal kann diese Anpassung zwar als Sonderfall
einer Einzel-Agenten-Adaption gesehen werden (Adaption des
Team-Leiters), aber die Problem-Klasse der Synthese von Team-Antworten
ist derart verschieden von den Problemen, die Einzelagenten
normalerweise bearbeiten, daß gänzlich andere Verfahren verwendet
werden müssen.
- Adaption der Architektur
Die Anzahl der aktiven Agenten und ihre Konnektivität kann im
Prinzip ebenfalls adaptiv an die aktuelle Problemsituation angepaßt
werden. Momentan erfolgt dies bei uns durch die Verwendung von
impliziter Konnektiviät. Diese Fragestellung ist auch Gegenstand
anderer Bereiche, wie zum Beispiel des Genetic Programming. Die meisten
dieser Ansätze versuchen ein "Züchten" von Architekturen aus sehr
elementaren Schaltelementen, etwa einzelnen Neuronen. Dieser Ansatz
erscheint aus unserer Sicht aufgrund der damit verbundenen
kombinatorischen Explosion von Architekturen wenig sinnvoll. Das andere
Extrem stellen Multi-Agenten-Systeme dar. Hier werden wenige sehr
komplexe Agenten - in der Regel komplette Experten-Systeme -
zusammengesetzt. Hierbei scheint uns die semantische Ebene der Agenten
jedoch zu hoch zu liegen. Beide Ansätze verwenden normalerweise feste
Konnektivitäten. Der Schlüssel zu einer guten Architektur scheint in
einer adäquaten mittleren Agent-Granularität sowie einer hinreichend
formbaren Konnektivität zu liegen. Beide Phänomene versuchen wir in
JANUS zu messen und zu modellieren.
- Schaffen neuer Agenten-Typen
In den Punkten 1 bis 3 ist die Modellklasse eines Agenten als
fest angenommen worden, das heißt, der Typ eines Agenten legt die
Basisfunktionalität instanzierter Agenten fest. Die Agenten optimieren
innerhalb der Freiheiten der Modellklasse. Um "wirklich flexibel" auf
�nderungen der Welt reagieren zu können, muß ein System eventuell auch
neue Basisfunktionalität entwickeln können. Eine zielgerichtete
automatische Entwicklung neuer Agenten-Typen ist derzeit jedoch
jenseits der technischen und wissenschaftlichen Möglichkeiten. Es gibt
keine anwendbaren Erkenntnisse über Gesetzmäßigkeiten einer Abbildung
"ungelöstes Problem" Ő "adäquate Modellklasse". Als einzige technische
Möglichkeit bleibt eine Zufallssuche nach neuen Modellen. Diese ist
aber angesichts der multidimensionalen Unendlichkeit der Möglichkeiten
selbst bei gerichteter Zufallssuche, etwa mit Genetischen Algorithmen,
auch bei trivialsten Problemen völlig aussichtslos. Aufgrund von
Reflexion kann JANUS zwar erkennen, daß neue Basisfunktionaliät
erforderlich ist, aber dann ist der Entwickler mit seiner menschlichen
Intelligenz gefordert, diese in Form neuer Agenten in das System
einzubringen.

Weitere Aspekete
Neben der Vielzahl von technischen Konzepten, die bei der
Implementierung
eines solchen recht großen Systems (rund 80000 Quellcodezeilen)
relevant
sind, entstehen auch neue Fragen auf der konzeptionellen Ebene. Ein
interessantes Beispiel :
Wenn man eine bestimmte Information auf dem Speicher markiert,
und ihren Weg durch die Agenten verfolgt, so gelangt man zu
Strukturenwie in Abbildung 8 gezeigt. Obwohl diese Strukturen im
wesentlichen aus einfachen Teams (wie in Abbildung 3) bestehen, können
sie bei einer Betrachtung auf niedrigster Ebene komplex und umfangreich
werden.
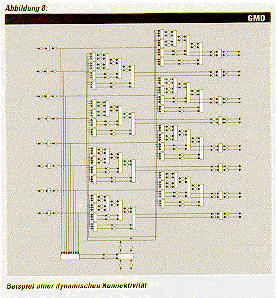
Diese Strukturen wachsen abhängig von der aktuellen Problem- und
Informationslage dynamisch und sind (obwohl implizit angelegt) nicht
explizit vordefiniert. Wenn die Funktionalität der Einzelagenten
hinreichend einfach ist, so ist ein solches Verhalten bezüglich
Erweiterbarkeit und Flexibilität des Systems einer festen Verdrahtung
deutlich überlegen, da man als Entwickler eine sehr lokale Sicht der
Agenten haben kann. Andererseits verliert man durch die extreme
kombinatorische Explosion der möglichen Konnektivitäten jede
Beweisbarkeit von nicht lokalen Fähigkeiten des Agenten-Systems. Das
System beginnt seine Entwickler zu "überraschen". So unangenehm ein
solcher Effekt für eine rein induktive Systembetrachtung ist, so
essentiell ist er auch mit der Idee eines "intelligenten" Verhaltens
verbunden. Um ein System ein "klein wenig intelligent" nennen zu
können, sollte es mindestens einmal in seiner "Lebenszeit" etwas
Sinnvolles leisten, was den eigenen Entwickler überrascht.
Perspektiven
Es ist offensichtlich, daß solche Konzepte wie Adaption, Reflexion,
Teams und Beschäftigung mit offenen "echten Welten" einerseits eine
Vielzahl von neuen wissenschaftlichen Fragen aufwerfen und andererseits
auch zu interessanten technischen Lösungen führen. Die Anzahl der
Möglichkeiten in dieser "neuen Dimension von Algorithmik" ist extrem
groß, und das Bestimmen einer sinnvollen "wissenschaftlichen
Suchrichtung" ist schwierig.
Wenn man der davon ausgehenden Faszination erliegt, so besteht
die ernste Gefahr, in eine "was wäre wenn" Welt abzugleiten und damit
jede Art von Wissenschaftlichkeit zugunsten eines "reinen Bastelwahns"
zu verlieren. Andererseits scheint die "offene Welt"-Eigenschaft
solcher Systeme einer klassischen induktiven Analyse nur begrenzt
zugänglich. Das heißt, die Exploration dieses Bereiches muß auf einer
Synthese von Formalismus und technischer Realisierung basieren. Ideen
müssen als technisch realisierbar bewiesen werden, und technische
Realisierungen müssen formal motivierbar sein. Gerade in diesem
Balance-Akt besteht der besondere Reiz und auch das große
wissenschaftliche Potential der nächsten Generation von "echte
Welt"-Systemen.

 |
Adaptive Systeme: Computer passen sich an
|
Von Gernot Richter
Ein System, das man adaptieren kann, ist damit noch nicht
adaptiv. Vielmehr muß es in der Lage sein, sich selbst an die
jeweiligen Umgebungsbedingungen -sozialer, technischer oder
biologischer Natur- anzupassen. Um den Bogen nicht allzu weit zu
spannen, befaßt sich der Beitrag mit programmierten informatischen,
also durch Software realisierten Systemen. Wenn ein System aufgrund
seiner bisherigen Geschichte zu Veränderungen fähig ist, die zu einer
Verbesserung seines zukünftigen Verhaltens führen, so ist es ganz
allgemein gesprochen adaptiv. Im Forschungsbereich Adaptive Systeme des
GMD-Instituts für Systementwurfstechnik werden solche Systeme erforscht
und entwickelt. Der folgende Beitrag gibt einen Überblick darüber,
welche Art von Adaptivität mit informatischen Systemen in diesem
Forschungsbereich angestrebt wird.
Bei dem Ziel, Adaptivität in technischen Systemen zu realisieren,
hat man als Inspirationsquelle die Anpassungsfähigkeit vor Augen, die
uns in der eigenen Alltagserfahrung oder in der Natur begegnet. Von der
Evolution kennen wir die sich über Jahrmillionen erstreckende Anpassung
an immer neue Lebensumstände. Oder betrachten wir die Bewältigung einer
neuartigen Aufgabe: Man probiert verschiedene Ansätze aus und überprüft
ihre Brauchbarkeit; die weitere Suche nach einer (besseren) Lösung
richtet sich nach dem bisherigen Erfolg oder Mißerfolg, sie wird dem
bisherigen Verlauf der Lösungssuche angepaßt. Ein anderes Beispiel:
Wenn man sich aus vorliegenden Daten eine Vorstellung über die
zukünftige Entwicklung eines technischen oder auch gesellschaftlichen
Prozesses gebildet hat, wird man diese Vorstellung beim Bekanntwerden
neuer Daten modifizieren, man wird sie an das nunmehr vorliegende
Datenmaterial anpassen. Und daß schließlich das Steuern eines Autos
eine anpassungsintensive Tätigkeit ist, bedarf wohl keiner weiteren
Erläuterung.
Immer leistungsfähigere Rechner gestatten es, adaptive Systeme mit
den Mitteln der Informatik zu realisieren und dabei heuristische
Verfahren einzusetzen, die sich an Vorbildern in der Natur orientieren,
aber nicht das Ziel verfolgen, sie zu imitieren: neuronale
Architekturen nach dem Vorbild natürlicher Nervensysteme und des
Gehirns, evolutionäre Algorithmen nach dem Vorbild der Evolution, der
Genetik und der Züchtung von Lebewesen, oder die Steuerung gegliederter
mechanischer Systeme (beispielsweise Roboter-Manipulatoren) nach dem
Vorbild biologischer Sensomotorik.
Gemeinsamer Hintergrund
Ein adaptives System interagiert mit einem Stück Welt, um ein Ziel zu
verfolgen oder eine Aufgabe zu lösen. Von diesem Stück Welt ist nur
unvollständig bekannt, wie es sich verhält, und es ist seinerseits
unbekannten, unvorhersehbaren oder unkontrollierbaren Einflüssen
ausgesetzt. Es ist offen zu seiner Umgebung hin. Damit operiert auch
das
adaptive System über die Interaktion mit dem betrachteten
Weltausschnitt
in einer offenen Welt. Eine Annahme über den unbekannten Weltausschnitt
ist allerdings unabdingbar, um sich überhaupt auf ihn einstellen zu
können: Von den dort entspringenden Daten muß angenommen werden, daß
ihnen erkennbare Gesetzmäßigkeiten zugrunde liegen - oder genauer:
daß zwischen den von außen herstellbaren Bedingungen, den Eingaben, und
den daraufhin eintretenden beobachtbaren Bedingungen, den Ausgaben, ein
Kausalzusammenhang hergestellt und damit postuliert werden kann. Unter
dieser Annahme können wir den betrachteten Weltausschnitt als gegebenes
System oder Objektsystem bezeichnen. Ihm gegenüber steht das adaptive
System, der Gegenstand unserer Forschungsarbeiten.
Warum will man sich mit einem weitgehend unbekannten und Störungen
ausgesetzten System überhaupt beschäftigen? Im letzten, um es zu
beherrschen. Sein Verhalten möglichst gut kennen oder möglichst gut
steuern können, das ist das Ziel. Und nur über Eingaben und die
Beobachtung der Ausgaben läßt es sich beherrschen. Man möchte zum
Beispiel
- eine Eingabe für das System finden, die zur bestmöglichen Ausgabe
führt (optimieren),
- zu einer gegebenen Eingabe die Ausgabe des Systems vorhersagen
(modellieren),
- das System aus dem vorliegenden Zustand, soweit er sich in der
beobachteten Ausgabe niederschlägt, in vorgegebener Weise durch eine
Folge
von Eingaben in einen neuen Zustand bringen (steuern, regeln).
Die Situation ist anders als bei einer Systemanalyse, die aus dem
Systemaufbau und den Beziehungen zwischen den Systemteilen Erkenntnisse
über das Systemverhalten und über die Folgen von Systemänderungen zu
gewinnen sucht. Hier dagegen kann das Objektsystem nur von außen
untersucht werden. Eine Analyse des Inneren ist im allgemeinen nicht
durchführbar: zu aufwendig, zu komplex, zu gefährlich, zu wenig
aufschlußreich, nicht verantwortbar, technisch nicht machbar. Man muß
sich also darauf beschränken, das Objektsystem als reine
Ein-/Ausgabe-Maschine (ohne innere Zustände) zu betrachten.
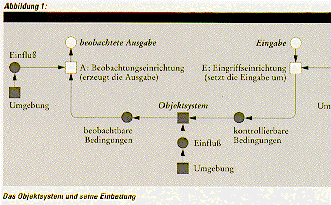
Bei der Beobachtung des Objektsystems und bei der Einwirkung auf
dieses System ist man auf Einrichtungen angewiesen, die den Zugang
vermitteln, jedoch ihrerseits Unschärfen und Störungen aufweisen. Sie
bilden die Schnittstelle des Objektsystems zur Außenwelt. Abbildung 1
stellt die Einbettung des Objektsystems schematisch dar. Die
Funktionseinheit E (Eingabe, Eingang) dient dazu, die beeinflußbaren
Betriebsbedingungen des unbekannten Objektsystems zu verändern. Die
Funktionseinheit A (Ausgabe, Ausgang) dient dazu, die beobachtbaren
Bedingungen oder Zustände des Systems zu erfassen beziehungsweise zu
messen. Dazwischen befindet sich das Objektsystem: eine technische
Anlage, ein Software-System, das eine komplexe Funktion implementiert,
ein Ökosystem oder ein anderes Stück Realität. Das adaptive System
stellt die Verbindung von der Ausgabe zur Eingabe her (im Diagramm
nicht dargestellt).
Um Objektsysteme zu beherrschen, entwickeln wir adaptive Systeme mit
zwei unterschiedlichen Zielen. Ein Erkundungssystem soll das Verhalten
des Systems herausfinden und dieses Wissen aufgabenbezogen einsetzen,
ein Steuerungssystem soll das Verhalten des Systems aufgabenbezogen
beeinflussen.
Ein Erkundungssystem enthält im allgemeinen eine Modellierungs- und
eine Anpassungskomponente. Die Modellierungskomponente soll das
Objektsystem möglichst gut nachbilden: zu Eingaben solche Ausgaben
erzeugen, die auch beim realen System entstehen würden. Die
Anpassungskomponente dient dazu, das Modell und/oder die Eingaben dem
bisherigen Verhalten des Objektsystems anzupassen.
Je nach Zielsetzung des Erkundungssystems sind zwei Fälle zu
unterscheiden.
Im einen Fall existiert bereits ein hinreichend gutes Modell des
Objektsystems. Es wird von der Anpassungskomponente dazu verwendet,
durch systematisches Ausprobieren eine Eingabe zu finden, die möglichst
nahe am Optimum liegt, das heißt, zu einer suboptimalen Ausgabe führt -
im allgemeinen, ohne daß man etwas über das (theoretische) Optimum oder
die es erzeugende Eingabe weiß. In diesem Fall werden die Eingaben an
den bisherigen Verlauf der Suche angepaßt (Optimierungsaufgabe),
während das Modell selbst unverändert bleibt. Im Abschnitt
"Evolutionäre Algorithmen" wird diese Art von Erkundungssystemen näher
erläutert.
Im anderen Fall läßt sich für das Objektsystem kein ausreichend
gutes Modell angeben. Die Anpassungskomponente dient hier dazu, die
Modellierungskomponente aufgrund von beobachteten Daten aus dem
Objektsystem zu verbessern. Hier wird also das Modell an die Daten
angepaßt. Diese Verwendung des Erkundungssystems ist Gegenstand der
Abschnitte "Reflektive statistische Lern- und Explorationsverfahren"
und "Adaptive Kontrolle in offenen Umgebungen".
Bei einem Steuerungssystem geht es darum, das Objektsystem in einen
bestimmten Zustand oder, allgemeiner, zu einem bestimmten Verhalten zu
bringen. Wir verwenden hier der Einfachheit halber die Wörter
"Steuerung", "Regelung" und "Kontrolle", ohne auf den technischen
Unterschied zwischen Steuern und Regeln einzugehen (vgl. DIN 19226).
Hier hängt die Reaktion des Objektsystems nicht nur von der Eingabe,
sondern auch von den "beobachtbaren Bedingungen" ab (Pfeilspitze zum
Objektsystem ist in Abbildung 1 zu ergänzen). Ein Steuerungssystem
besteht im allgemeinen aus einer Regelungs- und einer
Anpassungskomponente. Aufgabe der Regelungskomponente ist es, durch
geeignete Eingaben das Objektsystem so zu beeinflussen, daß die
jeweilige Soll/Ist-Abweichung und ihr zeitlicher Verlauf in
vorgegebenen Grenzen bleiben. Die Kontrollparameter und -regeln, gemäß
denen die Regelungskomponente das Objektsystem regelt, können
ihrerseits anhand von Aufzeichnungen des bisherigen Kontrollverlaufs
von der Anpassungskomponente an die zuletzt beobachtete Entwicklung
angepaßt werden. Im Abschnitt "Adaptive Kontrolle in offenen
Umgebungen" wird die prinzipielle Arbeitsweise eines Steuerungssystems
erläutert.
Arbeitsgebiet Evolutionäre Algorithmen
Unter dem Begriff "Evolutionäre Algorithmen" werden Verfahren
zusammengefaßt, die nach dem Vorbild der natürlichen Evolution Zufall
und gezieltes Vorgehen verbinden, um für eine gegebene Aufgabe eine
möglichst gute Lösung zu finden. In Begriffen der Mathematik sind das
Optimierungsprobleme: für Funktionen in hochdimensionalen Räumen sind
globale Extremwerte zu finden (vgl. den Aufsatz "Evolutionäre
Algorithmen: Optimieren nach dem Vorbild der biologischen Evolution";
Hans-Paul Schwefel, Ulrich Hammel, Thomas Bäck; GMD-Spiegel 1/2'94,
Seite 49 bis 58). Besonders schwierig ist dies bei Funktionen, die
viele lokale
Extremwerte besitzen (multimodale Funktionen) und für die es keine
mathematische Darstellung gibt, die ein Auffinden von Extremwerten mit
analytischen Mitteln gestatten würde. Solche Funktionen treten bei
zahlreichen praktischen Optimierungsproblemen als Zielfunktion auf.
Zwei Klassen von Optimierungsaufgaben sind zu unterscheiden.
Die eine Klasse von Aufgaben kann mit dem Ausloten eines unbekannten
Sees verglichen werden, dessen Grund nicht zu sehen ist. Man sitzt in
einem Boot und läßt ein Senkblei in die Tiefe. Sobald der Boden
erreicht ist, liest man die Tiefe ab und ordnet sie der Position auf
der Seeoberfläche zu. Bestenfalls weiß man, ob es sich um schroffen
Fels- oder hügeligen Sandboden handelt. Dies ist wichtig für die
Methodik des Suchens und die Plausibilität der Interpolation zwischen
den gemessenen Punkten. Ein Seegrund aus Sand oder Erde wird im
allgemeinen keine extrem steilen Schluchten oder Erhebungen aufweisen,
was aber bei einem Felsengrund nicht auszuschließen ist. Dort kann sich
die Wassertiefe wenige Zentimeter neben dem zuletzt vermessenen Punkt
sprunghaft ändern. Eine letzte Sicherheit vor Überraschungen kann es
nie geben: Auch aus einem Sandboden können Felsen hervorragen oder
versenkte Objekte zu abrupten Veränderungen des Abstands von der
Seeoberfläche führen. Erschwert wird die Suche nach der besten Lösung
(nach der tiefsten Stelle) im allgemeinen durch zusätzliche
Beschränkungen im Raum der möglichen Lösungen " bestimmte Bereiche des
Sees kommen nicht infrage.
Während man beim Ausloten eines Sees die Stelle, an der man sucht,
in beliebig kleinen Schritten " man sagt kontinuierlich " verändern
kann, gibt es andere Probleme, bei denen ein beliebig feines
Ausprobieren nicht möglich ist. Hier spricht man von der Optimierung
einer diskreten Funktion. In dem Beitrag "Genetische Algorithmen:
Transportoptimierung und Tourenplanung für ein zentrales
Auslieferungsdepot" von Andreas Reinholz wird eine diskrete
Optimierungsaufgabe beschrieben.
Evolutionäre Algorithmen sind heuristische Iterationsverfahren. Die
Anpassung der Suchschritte geschieht aufgrund von Beobachtungsdaten aus
dem nicht vorhersehbaren Verlauf der Extremwertsuche. Die Beschreibung
des problemspezifischen Zusammenhangs zwischen Eingabe (Position auf
dem See) und Ausgabe (Wassertiefe) liegt in Form einer algorithmisch
realisierten Funktion und zusätzlicher Beschränkungen vor. In einem
solchen Iterationsverfahren gibt es in der Regel nach jedem Schritt
mehrere Möglichkeiten, mit einer neuen Eingabe fortzufahren. Die
Auswahl des nächsten Schrittes und damit die Fortsetzung des
Lösungsweges wird in unterschiedlichem Ausmaß von den bisherigen
Ergebnissen abhängig gemacht. Entwicklung, Erprobung und theoretische
Analyse von Methoden und Systemen zur evolutionären Extremwertsuche,
insbesondere von solchen, die auf Genetik und Züchtung beruhen, sind
unsere Schwerpunkte in diesem Arbeitsgebiet.
Zwar ist der eigentliche Gegenstand der Erkundung das Objektsystem.
Da aber an diesem System das Ausprobieren von Eingaben normalerweise
nicht möglich ist, muß es erst modelliert und als
Modellierungskomponente des Erkundungssystems implementiert werden,
bevor man die Lösung des eigentlichen Problems, die Suche nach einem
Optimum, in Angriff nehmen kann.
Eine Eingabe ist ein strukturiertes Datenobjekt, das eine mögliche
Lösung der Aufgabe oder, mathematisch gesprochen, einen Punkt im
Definitionsbereich der Zielfunktion computergerecht repräsentiert. Als
Ausgabe bekommt man sozusagen "die Tiefe des Sees an diesem Punkt". Man
weiß aber nicht, ob der erhaltene Wert der bestmögliche ist
beziehungsweise, wie nahe er an dem bestmöglichen, dem theoretischen
Optimum, liegt. Die Kunst besteht nun darin, aus diesem Ergebnis, aus
der zugehörigen Eingabe und aus den vergangenen Versuchen eine neue
Eingabe zu ermitteln, von der man sich ein besseres Ergebnis verspricht.
Dies ist genau die Aufgabe der Anpassungskomponente eines
Erkundungssystems zur Funktionsoptimierung. Ist das neue Ergebnis
tatsächlich besser, spricht man von einer höheren Fitneß dieser
Eingabe. Deshalb wird die Zielfunktion in Anlehnung an die Terminologie
der Evolutionslehre auch Fitneßfunktion genannt.
In der natürlichen Evolution findet Entwicklung aber nicht dadurch
statt, daß ein Individuum nach dem anderen die Welt bevölkert, sondern
indem zahlreiche Individuen in unterschiedlichen Lebensumständen
verschiedene Fähigkeiten entwickeln, Populationen bilden, sich
gegenseitig beeinflussen und Nachkommen produzieren, die ihrerseits
einen Teil der Eigenschaften der Vorfahren als Anlagen enthalten. Der
Fortbestand einer Population ist vereinfacht gesagt dann gesichert,
wenn sie viele Individuen mit einer hohen Fitneß besitzt und diese sich
im Laufe der Generationen durchsetzen. Solche Gegebenheiten und
Vorgänge werden bei Evolutionären Algorithmen in stark vereinfachter
Weise im Computer nachgebildet.
Die Individuen sind (computergerechte Darstellungen von) Lösungen
der Optimierungsaufgabe. Mengen von Individuen entsprechen den
Populationen. Individuen mit höherer Fitneß werden bei der Produktion
neuer Individuen als "Eltern" bevorzugt, weil man hofft, in dieser
Richtung zu einem Optimum zu kommen: Wo der See tiefer wird, dort mißt
man weiter. Man kann sich vorstellen, daß bei Populationen von vielen
Tausend Individuen das Potential für paralleles Rechnen enorm ist: Der
See ist dann voller Boote mit Leuten, die nach tiefsten Punkten suchen
und sich ständig darüber abstimmen, wo sie weitersuchen wollen.
Was hier harmlos als Eingabe bezeichnet wird, ist eines der
Kernprobleme bei
den evolutionären Algorithmen: Wie lassen sich die in Betracht
kommenden
Lösungen für eine gegebene Optimierungsaufgabe so darstellen
(codieren), daß aus ihnen durch genetische Operationen weitere Lösungen
gewonnen werden können, für die dann ihrerseits die Fitneß berechnet
werden kann?
Das andere Kernproblem kann die Fitneßfunktion selbst sein. Während
bei einem Problem der Transportoptimierung die Verwendung einer aus der
Praxis (Objektsystem) entlehnten Kostenfunktion naheliegt, ist es bei
weniger offensichtlichen Fällen durchaus möglich, daß man - ebenfalls
durch intelligentes Ausprobieren - die angemessenste Fitneßfunktion
erst finden muß, indem man für die Modellierungskomponente den
"idealen" Satz von Parameterwerten sucht, nämlich jenen, mit dem sich
das Objektsystem am besten nachbilden läßt.
Arbeitsgebiet Reflektive statistische Lern- und
Explorationsverfahren
Hier geht es darum, die Modellierungskomponente eines Erkundungssystems
anhand von Beispielen, die aus dem Objektsystem stammen, so
einzustellen, daß sie das Ein-/Ausgabe-Verhalten dieses Systems
möglichst gut nachbilden kann " und zwar auch für Eingaben, zu denen
bisher keine Ausgaben vorgelegen haben. Unter einem Beispiel versteht
man ein Paar aus einer realen Eingabe und einer beobachteten Ausgabe,
wobei angenommen wird, daß die Ausgabe durch die Eingabe bewirkt wurde,
was im Einzelfall zu prüfen ist.
Für die Anpassung selbst, hier gewöhnlich als Lernen bezeichnet,
kann das Erkundungssystem vom Objektsystem auch entkoppelt sein. In
einem solchen Fall wird dem Erkundungssystem eine Menge von Beispielen
(Trainingsmenge) vorgelegt, die in der Vergangenheit aus dem
Objektsystem gewonnen wurden. Das Objektsystem wird für die
Anpassungsphase des Erkundungssystems gewissermaßen durch eine
Beispieldatenbank ersetzt. Dem offline-Lernen steht das online-Lernen
gegenüber, bei dem das Erkundungssystem durch direkte Interaktion mit
dem Objektsystem dessen Ein-/Ausgabe-Verhalten "herauszufinden"
versucht.
Die Grundidee des Lernens ist bei beiden Verfahren gleich: Das
Erkundungssystem berechnet mit seiner Modellierungskomponente aus den
Beispieleingaben die nach seinem Kenntnisstand zu erwartenden Ausgaben
und vergleicht diese mit den beobachteten Beispielausgaben. Den
Unterschied zwischen berechneten und tatsächlichen Ergebnissen
verwendet die Anpassungskomponente dazu, die Parameter der
Modellierungskomponente neu einzustellen, um das eigene
Ein-/Ausgabe-Verhalten dem aus den Beispielen erkennbaren anzupassen.
Das im Erkundungssystem entstehende Modell samt Parametern soll jene
Abbildung zwischen Ein- und Ausgabe realisieren, die bei gegebenem
Datenmaterial am plausibelsten ist. Man spricht hier von
Funktionsapproximation. Eine Anwendung ist die Vorhersage von Ausgaben
zu gegebenen Eingaben, weil man zum Beispiel die Konsequenzen einer
Entscheidung untersuchen möchte, bevor man eine Eingabe in das reale
Objektsystem gibt. Eine andere Anwendung ist die Klassifikation von
Eingaben nach vorgegebenen oder aus dem Datenmaterial abgeleiteten
Kriterien. Bei solchen Anwendungen ist die Klassenbezeichnung die
Ausgabe und das Objektsystem der Mensch, der zum Beispiel
handgeschiebene Zeichen erkennt (klassifiziert).
Die Beschaffenheit des Datenmaterials ist von entscheidender
Bedeutung für das Ergebnis der Anpassung. Je deutlicher das
(statistisch bereinigte) Datenmaterial einen Rückschluß auf eine
zugrunde liegende Gesetzmäßigkeit zuläßt, desto größer kann die
Sicherheit sein, daß die schließlich angepaßte Modellierungskomponente
auch für noch unbekannte Daten ein gutes Ergebnis liefert, sofern diese
Daten aus derselben Quelle (Anwendung) kommen. Das Modell des
Erkundungssystems ist damit in der Lage, das verwendete Datenmaterial
zu "verallgemeinern".
Die statistischen Ansätze, wie zum Beispiel neuronale Netze oder
nichtparametrische Regression, die wir in diesem Arbeitsgebiet
verwenden, gestatten es, die Zuverlässigkeit der durch Anpassung
entstandenen Modelle abzuschätzen oder aber durch gezieltes
Ausprobieren mit nur wenigen Beobachtungsdaten brauchbare Modelle zu
finden. Gerade der letzte Punkt, die sogenannte Exploration, verspricht
interessante Ergebnisse, weil man durch intelligentes Konstruieren von
Beispieleingaben an informative, das heißt, für die Anpassung wertvolle
Ein-/Ausgabe-Paare kommt. Wertvoll sind beispielsweise Paare aus
Bereichen, über die man noch wenig weiß, oder aus Bereichen, wo kleine
Veränderungen in der Eingabe große Schwankungen in der Ausgabe bewirken.
Für die geschickte Exploration, also die "Entnahme von Proben" aus
dem Objektsystem, ist eine Betrachtung des Verlaufs der bisherigen
Entnahme-Experimente, auch als Reflexion bezeichnet, unerläßlich. Die
Reflexion beginnt damit, daß die Modellierungskomponente begleitende
Aussagen zu ihren Ausgaben liefert, die von der Anpassungskomponente
als Zusatzinformation für die Anpassungsschritte verwendet werden
können. Ein Beispiel für derartige Aussagen ist die Zuversicht
(confidence), mit der eine berechnete Ausgabe aus der Sicht der
Modellierungskomponente aufgrund der verfügbaren Beispiele dem wahren
Wert entspricht (etwa eine Zahl zwischen 0 und 1). In dem Beitrag
"Konstruktive Datenerhebung mit reflektiven neuronalen Netzen" von Jörg
Kindermann und Gerhard Paaß in diesem Heft wird gezeigt, wie sich durch
intelligente Exploration die Zahl der zur Modellierung erforderlichen
Beispiele drastisch reduzieren läßt.
Arbeitsgebiet Adaptive Kontrolle in offenen Umgebungen
Beim Arbeitsgebiet Adaptive Kontrolle in offenen Umgebungen liegt das
Hauptinteresse zunächst auf dem Steuerungssystem, das in den anderen
beiden Arbeitsgebieten nicht in Erscheinung tritt. Es hat die Aufgabe,
das Objektsystem so zu beeinflussen, daß seine Ausgabe, also der
beobachtbare Zustand, möglichst nahe an vorgegebenen Werten liegt und
sich diesem Ziel in vorgegebener Weise nähert. Diesen Vorgang
bezeichnet man als Regeln. Man hat es hier mit mehreren unabhängigen
Teilsystemen zu tun, die aber teilweise voneinander abhängen:
Führungssystem, Steuerungssystem, Erkundungssystem und Objektsystem.
Das zielsetzende Führungssystem legt fest, in welchen Zustand das
Objektsystem gebracht werden soll und welche Zustandsübergänge in der
Zeit auf dem Weg dorthin durchlaufen werden sollen. Das
Steuerungssystem leitet daraus ab, wie es auf das Objektsystem
einzuwirken hat, um diese Vorgaben zu erfüllen. Während es sich darauf
einstellt, können sich aber die Vorgaben selbst ändern, also der
Zielzustand und die einzuhaltende Zustandskurve (Trajektorie). Und
gleichzeitig ist das Objektsystem in ständiger, nur beschränkt
vorhersehbarer Änderung begriffen: das Transportsystem eines großen
Unternehmens läuft weiter und wird vom übrigen Verkehrsgeschehen
mitbeeinflußt, das Ökosystem ist ständig aktiv und unterliegt
unzähligen Einflußfaktoren, das technische System mit seiner Umgebung
unterliegt Eingriffen von außen und reagiert auf Umwelteinflüsse und
interne Veränderungen, die nicht verhindert oder gesteuert werden
können. Hinzu kommt, daß das Objektsystem im allgemeinen auch das Tempo
(Zeitverhalten) bestimmt, mit dem man es lenken muß, will man
unerwünschtes Verhalten vermeiden.
Es kommt also darauf an, daß das Steuerungssystem die Vorgaben auf
der einen Seite und das Objektsystem auf der anderen Seite ständig
beobachtet und schnell und zielgerichtet reagiert, wenn dazu Anlaß
besteht. Dazu werden in kurzen Abständen Ziel und Verlauf der
Zustandsänderungen mit dem realen Geschehen " soweit feststellbar "
verglichen. Aus dem Soll/Ist-Vergleich lassen sich die Werte für die
Stellgrößen (so nennt man die Eingabe in der Regelungstechnik)
ermitteln. Typisch für diese Art von adaptiven Systemen ist also der
enge Wirkzusammenhang zwischen dem Steuerungssystem und einem in der
Außenwelt ablaufenden, meist technischen Vorgang.
Die Komplexität des Objektsystems, seine Eigendynamik und die
unvollständige Kenntnis über sein Verhalten machen es erforderlich,
erfahrungsgestützte Annahmen zu treffen, um aus dem Unterschied
zwischen Soll- und Ist-Werten jene Eingaben zu ermitteln, die in der
momentanen Systemsituation zu einer Verringerung dieses Unterschieds
entlang der vorgegebenen Zustandskurve führen. Die Annahmen können in
parametrisierter Form in das Steuerungssystem eingebaut sein und im
Laufe der Zeit durch immer bessere Parametereinstellungen an die
aktuelle Steuerungsaufgabe angepaßt werden. In die Anpassung der
sogenannten Kontrollparameter fließen auch die Erfahrungen aus
vergangenen Steuerungsmaßnahmen ein, soweit sie von der
Anpassungskomponente aufgezeichnet wurden. Da das Objektsystem, während
es gesteuert wird, auch von außen beeinflußt wird, spricht man von
einer offenen Umgebung, in der die Steuerung stattfindet.
Bewegen sich die Echtzeitanforderungen an das Steuerungssystem in
Bereichen, die dem Aufwand für die Ermittlung der Stellgrößen enge
Grenzen setzen, so erweist sich die Offenheit des Systems als besondere
Herausforderung. Es müssen Verfahren gefunden werden, die in kurzer
Zeit (bei technischen Systemen manchmal unter 100 Millisekunden) so
gute Werte erzeugen, daß sich das Objektsystem halbwegs in die
gewünschte Richtung bewegt und keine der ihm gesetzten Schranken
verletzt. Aufwendige mathematische Berechnungen sind dann nicht immer
anwendbar. An ihre Stelle treten inkrementelle heuristische Verfahren,
mit denen ein hohes Maß an dynamischer Anpassung in dem vom
Objektsystem vorgegebenen Zeitrahmen erreicht wird.
Offenheit und adaptives Verhalten gehören zusammen. Am Beispiel
einer Manipulatorsteuerung wird dies klar (vgl. den Aufsatz "Wie
Roboter greifen und schreiben lernen können", Gernot Richter,
GMD-Spiegel 3Ő94, Seite 54 bis 65). Die physikalischen Eigenschaften
des technischen Systems und seiner Umgebung ändern sich im Laufe der
Zeit und mit unterschiedlicher Häufigkeit. Neue
Hinderniskonstellationen, Abnutzungseffekte an den mechanischen Teilen
der Manipulatoren, unterschiedliche Drehmomente an den Armgelenken,
wechselnde Gewichte der handzuhabenden Gegenstände, unbekannte Qualität
sowie allmähliche Änderung der Betriebseigenschaften von Sensoren " all
dies stellt hohe Anforderungen an die Anpassungsfähigkeit des
Steuerungssystems.
Es kann zweckmäßig sein, neben dem Steuerungssystem ein
Erkundungssystem vorzusehen, das die für die Steuerung wesentlichen
Betriebseigenschaften des Objektsystems nachbildet. Damit kann das
Steuerungssystem durch Ausprobieren am Modell besonders günstige
Stellgrößen finden, soweit dies die verfügbare Zeit im Kontrollzyklus
zuläßt.
Selbstanpassung und Lernen treten in diesem Arbeitsgebiet an zwei
Stellen auf: Im Steuerungssystem werden die Kontrollregeln und
-parameter gelernt, was zu einer verbesserten Anpassung der
Regelungskomponente führt. Im Erkundungssystem werden die
Modellparameter gelernt, mit denen die Modellierungskomponente das
regelungsrelevante Verhalten des Objektsystems nachbildet.
Schlußbemerkungen
Die drei Arbeitsgebiete des Forschungsbereichs Adaptive Systeme wurden
im wesentlichen isoliert dargestellt, das heißt, offensichtliche und
weniger offensichtliche Querbezüge wurden nicht angesprochen. Die Idee
ist naheliegend, unterschiedliche Adaptionsverfahren geschickt zu
kombinieren, um zu noch besser angepaßtem Verhalten eines
modellierenden oder regelnden Systems zu kommen. In Einzelfällen haben
wir damit erste Erfahrungen gesammelt, stehen aber im wesentlichen noch
am Anfang. Die Arbeiten der nächsten Jahre sollen zeigen, wie weit man
hier gehen kann.
Zusammenfassend läßt sich sagen, daß die gemeinsame
Forschungsaufgabe des Bereichs Adaptive Systeme darin besteht,
informatische Syteme zu entwerfen und prototypisch zu realisieren, die
sich durch ein hohes Maß an Flexibilität gegenüber Unbekanntem und
Unvorhersehbarem auszeichnen. Sie sollen in der Lage sein, auch bei
unvollständigem oder unscharfem Wissen (Daten, Regeln), gestützt auf
ungenaue Beobachtungen und innerhalb zeitlicher Grenzen Eigenschaften
unbekannter Systeme herauszufinden, um mit diesen Erkenntnissen deren
Ein-/Ausgabe-Verhalten optimieren, vorhersagen und steuern zu können.
Langfristig wird im Forschungsbereich Adaptive Systeme angestrebt,
gesicherte allgemeine Aussagen über den Entwurf solcher Systeme und
über deren statische und dynamische Eigenschaften zu gewinnen. Auf dem
Weg dorthin werden auch in Zukunft konkrete Entwicklungen von adaptiven
Systemen durchgeführt werden, weil vielfach nur mit experimentellem
Vorgehen Erkenntnisse über adaptives Verhalten und Anregungen für
Systematisierung und Theoriebildung zu gewinnen sind. Nicht zuletzt
dienen die Implementierungen auch dazu, Entwurfsvarianten und
Forschungsergebnisse anhand konkreter Anwendungen zu validieren.
