 An example of adaptive
behavior
An example of adaptive
behavior
The Idea
To enable JANUS to work well in an open world, the heuristic-based
methods must be also have the ability to learn by themselves. This is
enabled by collecting experience of good behavior while executing
tasks. Such knowledge can be used later to produce good behavior in
new but similar situations.
The Task
In this example, JANUS has to execute a touch-mission with its
left
hand.
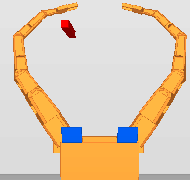

The left picture shows the initial position and the right picture
the
desired position.
Unfortunately a red column lies directly between
start and goal. Therefore measures must be taken to nogotiate the
obstacle.
Novice Phase
At the beginning of this phase, JANUS does not know how to get around
the red column in an elegant way. Therefore it tries a few
times to find simply a valid way around.
 Collecting
experience
Collecting
experience
During this phase JANUS learns a lot about movements that are
impossible if an obstacle lies in a similar position to the red
column. This knowledge is stored in form of imaginary obstacles which
are inserted in the thinking process if JANUS discovers that the arm
has some problems carrying out a specific plan. The following films
give a rough idea of how this knowledge is built up and used. The blue
cubes mark the virtual obstacles and the red line shows the desired
path (the plan) to be taken by the TCP. The schedule corresponds to
the movements shown in the previous film
Remembering "bad regions"
All in all it does not look too elegant, but JANUS can solve the
task
after a reasonable period of learning using imaginary obstacles.
Expert Phase
Now JANUS is an "expert" for obstacles that have similar properties as
the red column and which are located in a similar position.
For a new task that has a similar (in terms of blocking effect) set of
obstacles, JANUS reuses parts of the above knowledge and
immediately constructs the following plan.
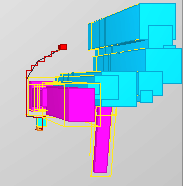
The execution of this plan looks like :
Applying knowledge
allowing JANUS to perform a reasonable touch straight away.
Is this a general solution to obstacle avoidance problems?
No of course not. The mechanism shown above works for surprisingly
many situations, but not for all possible ones. In the context of the
JANUS experiment this is to be expected, because the overall mechanism
behind the control of JANUS is achieved using a set of many simple "90
percent good heuristics". We achieve a
reasonable overall behavior by using combinations of heuristics and
learning at various levels of behavior.